3.1 How can we define life?
Previously, we defined biochemistry and molecular biology as the study of chemical processes within and relating to living organisms. But how do we define life itself? This might seem like a simple question, but there is no single, widely accepted definition of life. Even biologists (who study life) don’t agree on what ‘life’ is! When we think about life, most often our definitions are operational. That is, they allow us to differentiate non-living matter from living matter but don’t give a definition for life.
If you search for a succinct definition of life you might come across NASA’s contribution:
Life is a self-sustaining chemical system capable of Darwinian evolution.
This compact definition was formulated for astrobiologists. These scientists are searching for extraterrestrial life and do not want to be restricted to a definition that applies only to the example of life on Earth. However, the NASA definition is controversial. It is broad enough to encompass viruses, which most biologists would not include as living organisms, and it may exclude organisms not capable of reproduction such as mules (which are sterile, even though we would agree that a mule is alive).
Given that life is so difficult to define, rather than attempting to provide a succinct yet all-encompassing answer, it is more useful to describe life or living things by their common characteristics. These include:
- Organisation
- Metabolism
- Homeostasis
- Growth, reproduction and evolution
Organisation
Living systems are organised, meaning simply that they are arranged in a particular manner. When we use the term organised in biology it includes two fundamental ideas. One is that in living systems, things are arranged in a hierarchical manner; the other idea is that living systems tend to be less random than their surrounding environment.
The hierarchy of organisation
Living systems exhibit a hierarchical level of organisation where each level of the hierarchy exhibits greater complexity then the previous level and is comprised of components from the previous level.
Understanding this hierarchy is the key to understanding how life works mechanistically; that is, how all the components fit together.
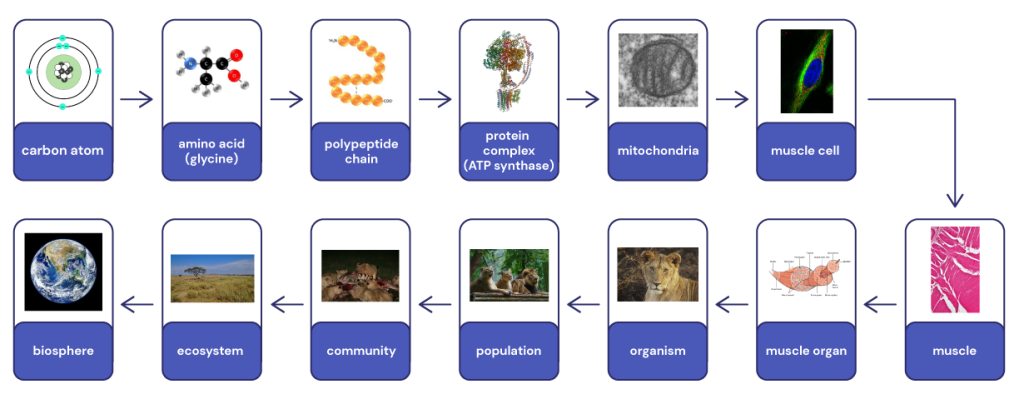
We will go into more depth with the common components of life, but it is worth getting an overview of them now. Figure 3.1 demonstrates this hierarchical organisation of life, starting with amino acids and proteins. We could certainly show a similar hierarchy using DNA, lipids (fats) or sugars as the example.
We can think of the hierarchy of organisation of life beginning with atoms forming molecules. The most common elements found in living organisms are carbon, hydrogen, oxygen and nitrogen (two other relatively common elements are phosphorous and sulphur). Atoms from these elements make up about 96% of any life form. For example, hydrogen and oxygen atoms combine to form water, which a major component of all living things.
Molecules can combine to form more complex molecules such as amino acids. Some of these molecules can combine further to form macromolecules such as proteins. These macromolecules can combine further to form complexes such as chromosomes, or large protein complexes which themselves provide the basic architecture of cells.
Cells are common to all living things and are considered the fundamental unit of life. That is, a cell is the smallest unit that we consider to be alive. A living organism can be a single cell, or it can be multicellular. In multicellular organisms, the organisation can be incredibly complex, with many different types of specialised cells. These cells can cluster to form tissues which in turn form organs and organ systems, which make up the organism. The hierarchy continues as communities of organisms interact with their physical environment to create ecosystems. All the ecosystems on Earth together form the biosphere.
How does this organisation come about?
How organisations arise is not a trivial question. By understanding it you will understand a key concept in biochemistry – that a constant input of energy is needed in order to maintain life.
The second law of thermodynamics states that:
the entropy of isolated systems left to spontaneous evolution cannot decrease as they always arrive at a state of thermodynamic equilibrium where the entropy is highest at the given internal energy.
Okay, so what does this mean?
First, we need to define what is meant by entropy. Entropy is a measurable physical property that is associated with disorder, randomness and uncertainty. So the second law of thermodynamics is stating that isolated systems will tend to become more random and disordered over time.
A good analogy is a neatly stacked pile of bricks. Over time you might expect some bricks to fall and the stack to eventually collapse. Another good analogy might be your bedroom which, if like the authors’, tends to become messy and disorganised over time! The reverse – reforming a neat stack of bricks or tidying your bedroom – won’t happen spontaneously. You must put some energy (work) into the system.

But living systems exhibit complex organisation, which represents a decrease in entropy. Does that mean that life violates the second law of thermodynamics?
The answer is no because living systems are not isolated. Energy enters the system (on Earth, primarily from the Sun) and is used to decrease entropy locally. This local decrease in entropy is compensated by an increase in entropy somewhere else. For our stack of bricks, if a worker were to restack a random (disordered) pile of bricks (decreasing local entropy), they would release heat from their muscles and small molecules such as carbon dioxide and water broken down from larger molecules in food by their metabolism (increasing the entropy of the universe).
The complex organisation that living systems exhibit means they are in a state of thermal disequilibrium – they can only maintain order via a constant input of energy. Note that this is possibly the characteristic of living systems that would be most useful for astrobiologists trying to find extraterrestrial life. That is, since we have no idea of the form extraterrestrial life might take, it might be better to just look for a local region of decreased entropy (less randomness, increased organisation) relative to the surroundings!
The concept that energy is required for maintaining the hierarchical organisation exhibited by life will help us understand the next important characteristic of all life – metabolism.
Metabolism
As mentioned above, organisms need to maintain a non-equilibrium state with respect to energy. They do this by importing chemicals to produce energy that can be used to drive various cellular processes. Metabolism is the term used to describe all the chemical reactions involved in these cellular processes. These chemical reactions are essential to life as they provide the energy and the basic building blocks that enable organisms to maintain their complex organisation, grow and reproduce.
The fact that chemicals need to be imported into the cell means that the cell needs to be defined by a perimeter. A distinct boundary between the organism and the rest of the world is required. The basic barrier for all organisms is a cell membrane, and it appears to be a homologous structure across all organisms. That is, cell membranes were present in the common ancestor to all life and have been inherited ever since.
Organisms may confine their metabolic reactions to within cells, but they must also exchange resources with their environment. Organisms are able to import (capture), in a controlled manner, energy and matter (nutrients) from their environment and to export (excrete) waste products to their environment. It is the cell membrane that modulates the transport of chemicals into and out of cells and is thus critical to metabolism.
How can metabolism create order?
In the previous section we saw that life represents a local decrease in entropy that must be balanced by an overall increase in entropy of the universe. What is the nature of that entropy increase?
Remember that systems tend toward disorder rather than order. This means that chemical reactions that create order, such as the activity of complex macromolecules and structures within cells, are still ‘unfavourable’ in that they lead to an overall decrease in entropy.
So, imported energy is used to drive thermodynamically unfavourable chemical reactions, creating disequilibrium with the environment. As we saw, this is represented by, say, the release of small molecules such as carbon dioxide and water from breaking down larger food molecules and the release of heat from these chemical reactions.
Types of metabolism
We can broadly categorise metabolism into two processes: catabolism (obtaining energy from nutrients) and anabolism (production of new cell components, usually through processes that require the power obtained from nutrient catabolism). The key to understanding metabolism is that these processes are linked; that is, catabolic processes are used to drive anabolic processes.
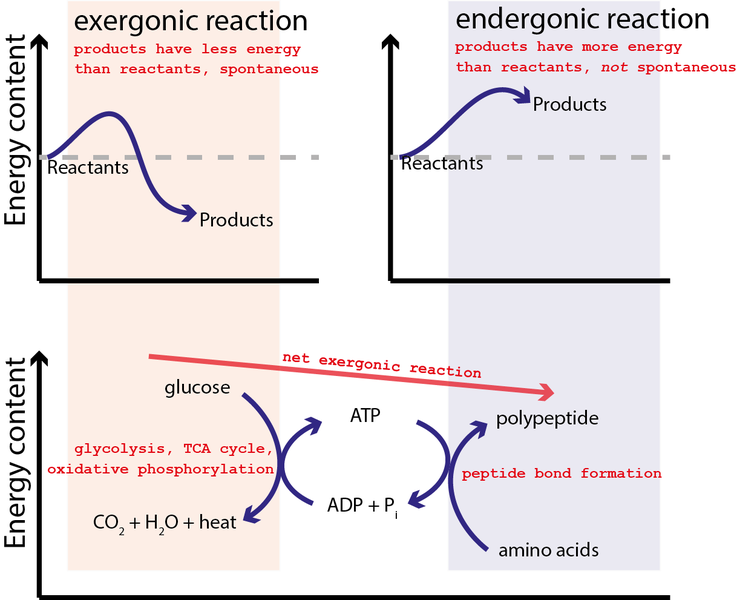
A chemical reaction will not proceed spontaneously unless the products of the reaction have lower energy than the reactants, so that some energy is available from and released by the process. What we mean here by energy is ‘free energy’. In simple terms free energy is a measure of the capacity of the system to do work.
This can be more easily understood if we look at a familiar chemical reaction like the combustion of petrol. Octane (a molecule in petrol) contains more energy than the water and carbon dioxide molecules that are released after burning the petrol. This means that the reaction has the capacity to do work, such as drive an internal combustion engine. Combustion is an example of an exergonic reaction, in which the reactants have more energy than the products.
Conversely, when the free energy of the products is greater than the reactants, the reaction is known as endergonic. Endergonic reactions can only proceed when there is an input of energy. Given that many of the reactions in a cell are endergonic, such as the production of macromolecule polymers such as proteins from amino acids, how can these occur?
The answer is by coupling exergonic and endergonic reactions, so the free energy provided by the first (exergonic) reaction can be used to fuel the second (endergonic) process. The metabolism of glucose to produce ATP to fuel polypeptide synthesis is a good example.
Homeostasis
Homeostasis (from the Greek words for same and steady) in essence means a maintenance of stability. In biological systems, all living organisms actively use processes to maintain the internal conditions necessary for survival. So, while living systems may appear to be constant – in other words, in a steady state – they require continual work (energy input) to maintain, and they are never actually at equilibrium.
The processes that control the internal conditions of an organism are driven by negative feedback loops. For example, many organisms need to maintain a relatively constant internal temperature. Any change in external conditions that leads to a change in body temperature triggers a process to counteract that change – in humans that process might be shivering if externally it is colder than internally or sweating if it hotter. These kinds of homeostatic processes are involved in maintaining all of the key conditions in organisms: pH, nutrient levels, electrolyte concentrations and so on.
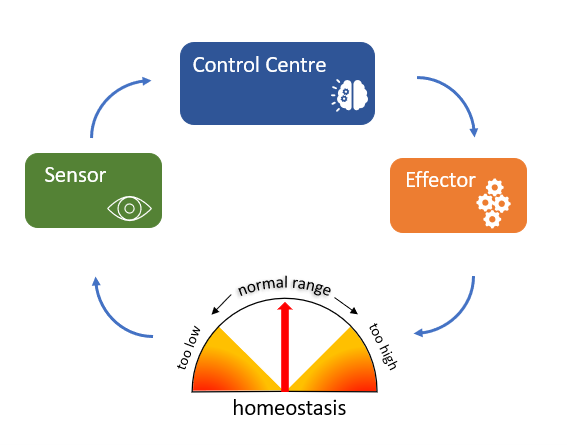
Though we can understand homeostasis at the broad physiological level when we think of something like body temperature in humans, ultimately there is a cellular and molecular basis for homeostasis. This differs from process to process but there is some commonality. All homeostatic control mechanisms can be likened to a simple machine and have at least three interdependent components: a sensor, a control centre and an effector (see Figure 3.4).
For example, the levels of a physiological variable like blood glucose need to be maintained within an optimal range despite food intake and physiological status. If glucose levels rise above this optimal range, receptors in the body are activated (sensors), and these receptors in turn stimulate the pancreas (control centre) to release insulin (effector). Insulin stimulates the liver to take up blood glucose and store it as glycogen (a polymer of glucose monomers), thereby reducing blood glucose levels to within the optimal range and maintaining homeostasis.
One of the major goals of biochemistry is to understand the molecular mechanisms that underlie homeostasis by mechanistically characterising these components; that is, determining how they fit together and work. Being able to understand and identify negative feedback loops is key to understanding the majority of cellular processes.
Growth, reproduction and evolution
The final key characteristics shared by all life are growth, reproduction and evolution. You might wonder why these are grouped as such, but you will see that they are very much intertwined.
Growth by itself cannot be a defining characteristic of life as many non-living things grow, such as such as mountains or crystals. These non-living things generally grow by accretion – material is accumulated on their outside over time. Living things, on the other hand, grow from internal processes. This growth (unlike simple accretion of matter) is usually characterised by some transformative change, which we call development.
The twin characteristics of growth in living organisms are an increase in mass and an increase in the number of individuals (reproduction). In multicellular organisms, growth occurs by cell division, which may occur continually through the life of the organism (e.g. in many plants) or only up to a certain age (e.g. in most animals). Unicellular organisms such as bacteria also grow by cell division, so cell division is their means of reproduction (growth).
In the majority of higher ordered multicellular organisms, growth (increase in mass) and reproduction (increase in number) are mutually exclusive events and cell division is the means of tissue growth and maintenance. To slightly complicate things, cell division and cell growth are not always the same thing in all organisms. It is possible that cells divide repeatedly without exhibiting any growth. This is seen in very early embryo development of a number of organisms where the fertilised egg cell simply partitions itself into many cells without increasing mass.
Unicellular organisms and individual cells within multicellular organisms cannot simply divide ad infinitum (forever), otherwise they would become smaller with each division! The individual cells must increase in size and alter their composition to prepare for further cell division. So even individual cells demonstrate growth and development. The processes governing the growth and development of individual cells is known as the cell cycle. This is a repeating series of processes where cells acquire materials, synthesise molecules from them and partition these materials into two daughter cells.
So, if all living things grow in terms of increasing mass and by development, and all living systems are capable of reproduction, how is this linked to evolution?
What is evolution?
Evolution is described in a number of different ways by different people. Some definitions are much more expansive than others and often incorporate the term adaptation. Charles Darwin, in his book On the Origin of Species, did not use the term evolution but instead described the process of species development as ‘descent with modification’. This is a useful definition and we can reword it to:
Evolution is the change in the characteristics of a species over several generations.
The fact that this definition mentions ‘generations’ links the changes in characteristics of species to reproduction and therefore implies that these are heritable changes. For a change to be heritable (able to be passed from parent to offspring) it must happen to genetic material (i.e. DNA).
This may appear initially contradictory. You might imagine that for reproduction to occur successfully, DNA must be copied faithfully and passed onto the offspring (see Chapter 4). This is largely true but at the same time, evolution would not be possible without changes to DNA. The answer to this apparent contradiction is that change does occur to DNA during reproduction, but it is limited.
There are two ways in which DNA changes: by mutation and, in the case of species that reproduce sexually, by recombination. Mutations are changes to DNA that affect its sequence. Recombination occurs during meiosis, when maternal and paternal genes are regrouped into different combinations during the formation of gametes (sex cells). For the purposes of understanding evolution, we will only focus on mutation here.
How does DNA mutate?
For a cell to divide, first it must accurately and completely duplicate the genetic information encoded in its DNA. This is a complex problem because of the great length of DNA molecules. The cellular machinery that copies DNA is not perfect. Although it has a repair/correction function when it makes an error, a very small number of mistakes still slip through and remain coded. Plus, DNA can get damaged from things in the environment such as radiation or some chemicals.
The DNA in any cell in a multicellular organism can accumulate mutations but the only mutations that contribute to evolution are those that occur in germ cells (the cells that give rise to gametes – egg and sperm cells) as these cells contain the DNA that gets passed to the next generation. This brings up another important point – with evolution, individuals themselves do not change but instead there are changes to traits across generations.
Mutation is random!
It is important to emphasise this point as it is a source of confusion. Mutation does not occur in order to improve an organism (new traits do not arise in response to need). Mutation merely represents errors in genetic replication. Most of the changes (mutations) either do not cause any change to the characteristics of the species (they are neutral) or are in fact problematic (detrimental or deleterious). Very, very few mutations will be beneficial or advantageous in any way.
So, evolution is not possible without mutation, and mutation is not possible without a good possibility of some adverse consequences.
From this we can deduce that the heritable mutation rate must be very low. If it were high, it would put an impossible ‘genetic burden’ onto the next generation. They would be stuck with too many deleterious mutations to be able to live.
Now that we have the capability to easily sequence an entire genome (all of the DNA in an organism) we know how often mutations occur in reproduction. For example, we can see that for humans, at birth, children have about 70 new genetic mutations compared to their parents. This number makes sense given the size of the human genome (≈6.3 × 109 base pairs) and the known rate of mutation (≈1.1 × 10−8 per site per generation). If you multiply these numbers, you get an estimate of the number of mutations per generation.
6.3 × 109 (size of genome in base pairs)
× 1.1 × 10−8 (rate of mutation per base pair)
≈ 70 mutations per generation
Fortunately for us, these mutations appear randomly in our DNA sequence and most of our DNA (> 98%) does not directly affect our characteristics. Therefore most of these mutations won’t be problematic for us.
How does evolution occur?
Given the low rate of mutation and the fact that most mutations won’t really do anything (neutral mutations), how do species evolve? The answer is that mutation is not enough, and other processes embed mutations within a population or species.
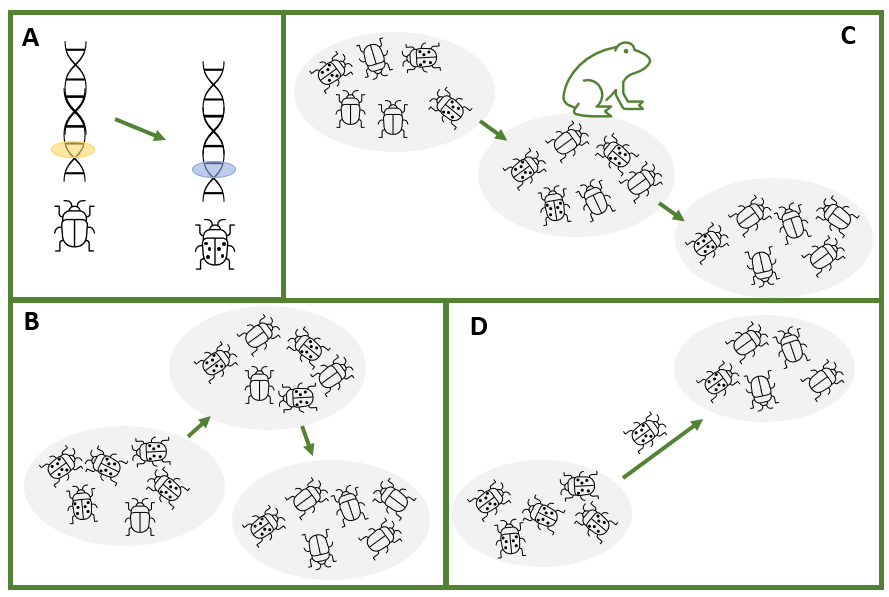
When a gene is mutated, it becomes slightly different. We refer to the variants of a particular gene as alleles. When we talk about changes to the characteristics of a population or species, what we are really discussing are the changes to the frequencies of alleles (gene variants) in the population or species. The major processes that affect the frequencies of alleles are natural selection, genetic drift and gene flow.
Some alleles give an organism a slight advantage in a particular environmental context. This advantage will manifest as increased success at reproduction (often described in genetic terms as fitness). This process is known as natural selection. In natural selection, the environment exerts a pressure on a population such that individuals with certain alleles will survive and reproduce more successfully. For example, individuals with a certain trait, say insects with more similar colouration to their habitat, might be less likely to be predated on by birds than insects of the same species with colouration that contrasts their habitat. If the predatory bird is present in the environment, a selective pressure will be exerted with respect to colouration.
Genetic drift occurs because the alleles that make it into the next generation in a population are a random sample of the alleles in a population in the current generation. Just by chance, not every allele will make it through; some will be over-represented while others will decline in frequency.
Gene flow can be thought of as a variation of genetic drift. When individuals migrate from one area to another, they bring with them different allele frequencies from the existing population. If there is subsequent limited mating with the existing population, coupled with different selective pressures in the new environment, substantial change can occur, including the evolution of new species.
The effects of genetic drift and gene flow can also manifest strongly when a population experiences a bottleneck in numbers (a rapid decrease for a period).
How did life on Earth arise?
The origin of life on Earth represents a conundrum, which is that on Earth today, all life comes from pre-existing life. But in principle life must have at some point arose abiotically (from non-living matter). We have evidence for life on Earth from around 3.5 billion years ago. The Earth is 4.6 billion years old, so it took perhaps a billion years for whatever chemical evolution took place to result in biological life.
Earlier ideas that microbial life ‘spontaneously generated’ from nutrient broth have been shown to be incorrect by careful experiment. So far, researchers have been unable to create a living and self-replicating cell from organic molecules, although a number of experiments have demonstrated that given the right conditions, the organic building blocks of life, such as amino acids, can form from inorganic precursors.
The problem is that all life contains complex macromolecules that are polymers (DNA is a polymer of nucleotides and proteins are a polymer of amino acids) but in extant cells, polymer formation is catalysed by enzymes which are proteins and therefore polymers themselves! There is some evidence that under the right conditions polymers such as RNA can spontaneously form from monomer precursors.
Even if polymers can spontaneously form, this leaves another problem. How could these polymers be self-replicating? The polymer would need to be both the hereditary molecule and make itself by being its own catalyst.
The RNA world hypothesis
This is problematic for DNA as there are no known natural DNA molecules that display catalytic activity. RNA, on the other hand, might be a better candidate. There are two differences that distinguish DNA from RNA. RNA contains the sugar ribose, while DNA contains the slightly different sugar deoxyribose (DNA’s sugar component lacks one oxygen atom compared to RNA’s), and RNA has the base uracil while DNA has thymine. These small differences in structure allow RNA to take on a much wider range of conformational structures than DNA.
Lending weight to the idea that RNA may have been the ancestral polymer of life was the discovery that RNA, because it could take on many different conformational structures, could also be catalytic. This discovery led to a Nobel prize in 1989 for US scientists Thomas Cech and Sidney Altman, who demonstrated that some RNA molecules can catalyse their own cleavage.
Catalytic RNA molecules are known as ribozymes. Ribozymes play universal and central roles in cellular information processing. The ribosome is a large complex of RNA and proteins that reads the genetic information in a strand of RNA to synthesise proteins. The key catalytic activity of the ribosome, the formation of peptide bonds to link two amino acids, is catalysed by its RNA component. The ribosome is actually a ribozyme!
With the possibility of catalytic RNA molecules, a single molecule or family of similar molecules could potentially store genetic information and replicate themselves, with no proteins needed initially. The discovery of ribozymes led to the formulation of the RNA world hypothesis. In this hypothesis, populations of catalytic RNA molecules undergo a molecular evolution conceptually identical to biological evolution by natural selection. RNA molecules would make copies of each other, making mistakes and generating variants. The variants that were most successful at replicating themselves would increase in frequency in the population of catalytic RNA molecules.
At some point in the lineage leading to our last universal common ancestor, DNA became the preferred long-term storage molecule for genetic information. This is probably because DNA molecules are more chemically stable than RNA (deoxyribose is more chemically inert than ribose). Also, having two complementary strands means that each strand of DNA can serve as a template for replication of its partner strand, providing some innate redundancy. These and possibly other traits gave cells with a DNA hereditary system a selective advantage so that now all cellular life on Earth uses DNA to store and transmit genetic information.
However, this is still just a hypothesis, and a different idea with many adherents is that metabolism in the form of self-sustaining networks of metabolic reactions may have come first . In this hypothesis, initially simple pathways might have produced molecules that acted as catalysts for the formation of more complex molecules. Eventually, the metabolic networks might have been able to build large molecules such as proteins and nucleic acids.
Regardless of the theory put forward for the initial self-replicating system, there are still many other questions. For example, a basic property of all cells is the ability to compartmentalise and maintain an internal environment distinct from the external environment. This is facilitated by encapsulation by a lipid membrane. How this first encapsulation took place and what lipids may have comprised the ancestral membranes remains a major question.
The oldest fossils
![]() Australia can claim the oldest fossils on Earth. These are found in Archean rocks from near Marble Bar in Western Australia. These fossils, known as stromatolites (Greek for layered rock), are layered sedimentary formations created by microorganisms and dated as approximately 3.45 billion years old. This is remarkable given that the oldest rocks on Earth date only fractionally older at 3.8 billion years. Initially, the idea that these fossils represented ancient life was controversial but recent isotopic analysis revealed that they were characteristic of biological matter.
Australia can claim the oldest fossils on Earth. These are found in Archean rocks from near Marble Bar in Western Australia. These fossils, known as stromatolites (Greek for layered rock), are layered sedimentary formations created by microorganisms and dated as approximately 3.45 billion years old. This is remarkable given that the oldest rocks on Earth date only fractionally older at 3.8 billion years. Initially, the idea that these fossils represented ancient life was controversial but recent isotopic analysis revealed that they were characteristic of biological matter.
During the time these fossils were formed the Earth’s atmosphere did not contain very much oxygen. Oxygen started appearing around 3 billion years ago and became more abundant around 2.5 to 2.3 billion years ago. It is speculated that these very early microorganisms may have used simplified photosynthesis that produced methane rather than oxygen. Eventually, species evolved like cyanobacteria (confusingly, sometimes called blue-green algae) which through photosynthesis fundamentally changed the Earth’s atmosphere by producing oxygen.
Australia is also one of the few places where you can find living versions of these stromatolites, in the shallow waters of Shark Bay, Western Australia. These living stromatolites are formed by photosynthetic cyanobacteria, and they provide us with a glimpse of what life may have been like for much of Earth’s biological history. These were the dominant fossil-forming organism for much of the Archean (4 billion to 2.5 billion years ago) and Proterozoic (2.5 billion to 541 million years ago) eras. Living stromatolites are made by a complex community of microbes and suggest the possibility of a similar complex community producing the ancient fossil stromatolites. If this is the case, it would mean that life first evolved well before 3.5 billion years ago!


{kind=link}
{kind=link}