Data – The Heart of the Healthcare System
Rachel Fojtik
Learning Outcomes
- Describe and apply the healthcare data management lifecycle to ensure ethical, efficient, and compliant data handling.
- Evaluate the role of the 5 A’s—Availability, Accessibility, Architecture, Ability, and Accuracy—in enhancing healthcare data usability and decision-making.
- Apply data governance principles to support high-quality, accountable, and sustainable data practices in healthcare.
Introduction
While health data have been managed and analysed in a handwritten format for centuries, the ability to analyse health data digitally is a much more recent development. Digital systems now enable professionals to efficiently record, access, store, and analyse individual patient records. Prioritising analysis in the implementation of these systems will significantly enhance their effectiveness for improving patient outcomes. This chapter explores several factors influencing the use of data in patient care, framed as the 5 A’s, which will serve as the backbone of our discussion on data usability from both data management and data literacy perspectives.
Understanding and managing the barriers to effective data use and the data management lifecycle—from creation to use and eventual destruction—is crucial for health information management professionals and health informaticians. Informed decision-making can significantly impact patient health outcomes throughout each phase of the data lifecycle. Although analysis of healthcare data has a long history, the digital analysis of health data is a relatively new advancement. As tools and processes for analysis have evolved, the sophistication and prevalence of digitally analysing health data have increased.
In this chapter you will learn:
- the fundamental concepts of data,
- the digital data management lifecycle,
- data governance principles,
- concepts of data analysis and turning data into usable information,
- data literacy, and
- visualisation.
This knowledge is essential for effective health information management in today’s digital era.
What is Data and Data Analysis?
Data consists of individual attributes that, when unorganised, are simply random potentially unidentifiable numbers, words, or letters. The table below shows a taxonomy with analogies of what the terms data, information, knowledge and wisdom reflect. If we look at data the row in the table below, lists the attributes of a tomato without any context. In the second row of the table, these attributes are more clearly categorised, which makes it possible to identify a tomato. In the next rows building on from data and information and leveraging the quote from Matt Kington (2003) “Knowledge is knowing that a tomato is a fruit; wisdom is not putting it in a fruit salad”. Similarly, data needs to be organised and understood to be useful. To take wisdom from knowledge it is necessary to add additional knowledge and expertise to it in the form of critical thought. (Zeleny 1987). This theory is known as Data, Information, Knowledge and Wisdom (DIKW) [opens in new tab] and is often portrayed in a pyramid.
| Taxonomy | Analogy | Processing & Storage Technology | Analytical Process |
|---|---|---|---|
| Data | Colour : Red, Shape: round, State: firm, contents:{juice, vitamin A, vitamin C}, Flavour : Sweet Plant : Vine | Tables, databases
(random attributes) |
Stored not analysed |
| Information | Tomato, grow on vines, high in vitamins A&C with a sweet taste | Information systems/reports
(organised data) |
Search and compile |
| Knowledge | Fruit, healthy | Visualisation Systems
Dashboards/Annotated Charts, Storytelling |
Analysis, Calculate and Compare |
| Wisdom | Do not put tomatoes in a fruit salad | Artificial intelligence, Large Language Models, Machine Learning | Judgement |
Data analysis involves taking information from data and organising it to gain insights. Everyday tasks, like crossing the street, involve data analysis. When crossing the street, we observe all objects around us, estimate distance and speed, and assess risk using our brain’s algorithmic capabilities. Despite our brain’s prowess, it has limits, making data processing tools essential to efficiently analyse vast amounts of data. The techniques used to analyse datasets and uncover patterns, trends, correlations, and other valuable insights are called data analytics. In more recent times, machine learning and artificial intelligence (AI) have greatly expanded opportunities for data analytics to improve patient outcomes (Reddy, 2023). Data analysis is the process of converting raw data into useful insights that can help generate wisdom (Zeleny, 1987), as examined later in this chapter.
The Importance of Data Analysis in Healthcare
In healthcare, practitioners evaluate a patient’s condition by examining various attributes and integrate their knowledge with additional information to make informed assessments. The more data available, the more accurate the diagnosis and subsequent treatment. Knowledge requires data and its analysis. The greater the volume of relevant data, the higher the accuracy. Healthcare professionals often face time constraints and require efficient methods to quickly analyse large data sets. Utilising data can significantly enhance the knowledge available to practitioners. Outcome data, for example a patient’s return to mobility post hip replacement is essential for clinical practice and remains challenging to capture effectively. One significant obstacle is the lack of a consistent feedback loop into the healthcare system. A further barrier is resourcing to support advanced data analytics capabilities in our healthcare organisations. Data from personal wearable devices, while highly private, holds substantial potential for providing valuable insights. Envision the immense value of outcome data collected at scale, enhanced by diagnostic, acute care, and allied health data. The opportunity for improving patient outcomes becomes immense. The clinical uses for data are shown in Figure 1. Further uses and benefits are discussed throughout this chapter.
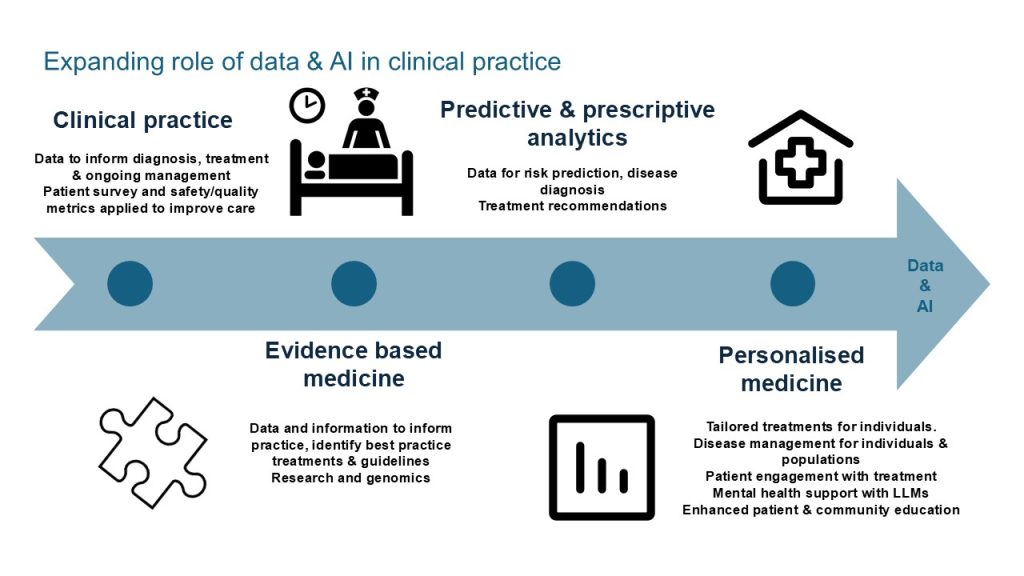
Historically, healthcare has generated vast amounts of data, primarily for record-keeping, patient care, and compliance with regulatory requirements (Raghupathi & Raghupathi, 2014). Currently, this data generation is further driven by wearable devices, genomics, and point-of-care diagnostics. When combined with AI, machine learning, and advanced models, these data sources present significant opportunities for enhancing healthcare (Alowais et al., 2023). Extensive data offers exciting opportunities for improving patient outcomes through enhanced care and medical research (Reddy, 2023). However, much of this vast data reservoir remains untapped. Five key factors impact whether data is used, which we will call the 5 A’s, as shown below in Figure 2 below.
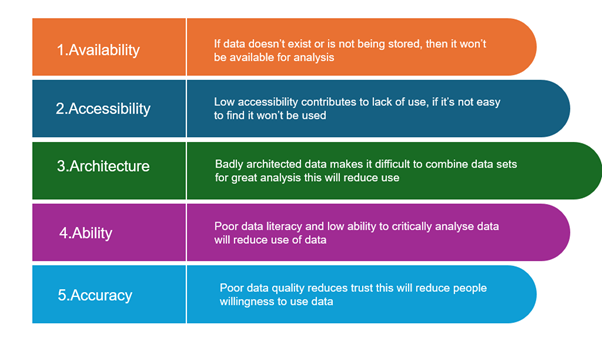
These five factors will be addressed throughout this chapter.
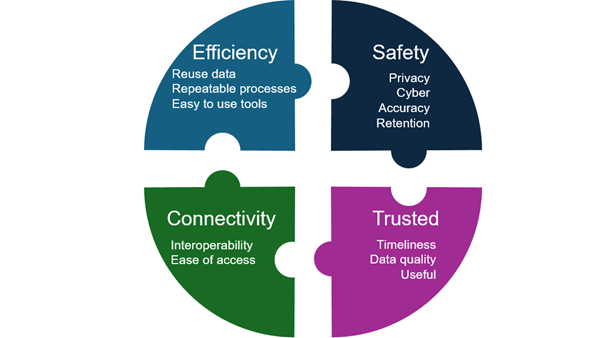
Many aspects of data management should be considered when gathering data for analysis, as shown in this Figure.
Data Management is the practice that this is referring to and the next section will cover the data management lifecycle.
Data Management Lifecycle
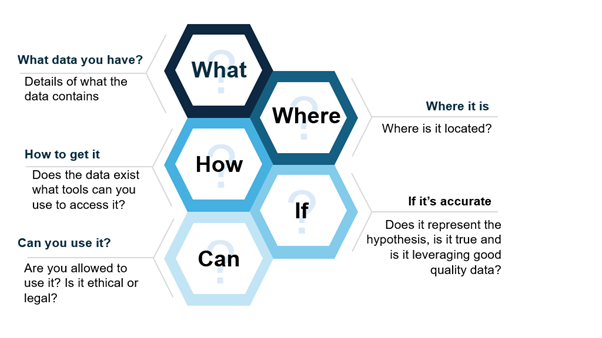
The data management lifecycle refers to the process of the creation through to the destruction of data, and is relevant to large scale data implementations in organisations all the way through to small data implementations for research. There have been many well publicised cases of data breaches in the health industry where adequate protection around the information asset has failed. To read further see chapters on Health Information Law, Privacy and Ethics and Cybersecurity in Health. Managing data is complicated and must be carefully considered throughout its entire life span. The figure below depicts the knowledge you require about the data you are using for decision making.
As a valuable asset, data should be managed with care (Miller et al., 2018). Lifecycle models provide structured guidance on data management, with decision points facilitating preparation (Ball, 2012). Data storage and governance should be considered throughout the lifecycle; however, in many models, it is only a point in the lifecycle. The Research Data Management Lifecycle that suits research (Harvard, n.d.), and the Data Lifecycle Framework for data driven governments model (Nayak and Puri, 2021) address broader needs when combined. The Figure below depicts a combined model adapted from these models to suit healthcare and research. The diagram shows the ways data is captured, cleansed and prepared, analysed, visualised and evaluated, shared and disseminated. Once data is no longer able to be used it is disposed of through archive and retention practices.
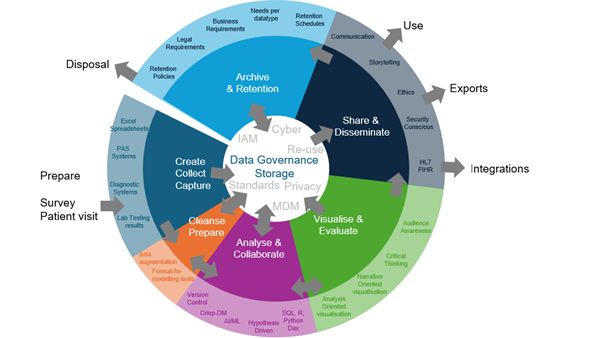
This section discusses key areas relevant to the data management lifecycle from the Figure. At its centre are storage and data governance, which remain important throughout the data lifecycle. The arrows pointing outside the circle in the Figure above, indicate data leaving the control of its original environment. A common challenge when sharing data is ensuring that once it is shared or disposed of, it enters another system or to individuals who will maintain similar levels of governance. Both the Data Lifecycle Framework and the Research Data Management Lifecycle approaches that this model was based on include planning as a stage, but here this is added as an input to the data management lifecycle, as the data do not yet exist. In the first stage, data are created, collected from another system, or edited in the existing system. They can then be stored or prepared for analysis, considering data integrity rules. Cleansed data go back to storage or to the analysis stage. Post-analysis, data return to storage or move to visualisation and evaluation. They can then be stored or shared, either fully analysed or as originally collected. Integrations typically receive data as collected or after minimal transformation. Once the data or analysis is no longer useful, it should be archived or disposed of.
Data Governance
Data governance is a practice that applies rules, standards, and guidelines specifically to ensure that data are well protected, accurate, and easily consumable for ethical decision making (Khatri & Brown, 2010). Data governance involves the allocation of decision rights and the accountability for decision-making concerning an organisation’s data assets to the areas of the business responsible for its entry and use (Khatri & Brown, 2010).
Unfortunately, this sounds easier than it is. Individuals that enter the data (clinicians, administrative staff and others) normally enter it throughout a process and are not normally the same people that use the data for decision making (potentially data owners). Individuals that store and manage the data (potentially data custodians or technical stewards) are often expected to be responsible for it, but do not create or use the data. This causes significant gaps in data quality, data security, and data availability, and this gap also results in a level of apathy in decision making on matters related to data governance that can only be resolved by clear roles and responsibilities with high levels of accountability and a very clear reason.
Gaining cooperation and support from data owners can be challenging due to time constraints and the additional costs required to ensure the correct procedures are followed. It is therefore essential to identify appropriate data owners and focus solely on important factors. Highlighting the significance of their responsibilities, the benefits for them, and incorporating data responsibilities into their job descriptions can contribute to effective data governance. Maintaining sustainable data governance requires integration with business processes and a focus on important factors.
Data governance involves determining the scope of what is being governed; who is responsible for the governance; the rules, guidelines, and standards they must use; as well as where the rules may be relaxed. This often requires upskilling those responsible for creating data and also aligning data decision making with business process decision making.
In this context, data governance professionals are responsible for aligning owners, custodians, and stewards and ensuring that they are aware of and understand their responsibilities. This can be done by creating forums or councils for data owners, maintaining focus, holding them accountable, and providing visibility for what needs to be managed. A data governance manager must receive strong support from senior leadership, be persuasive, and excel at coordinating people.
To implement data governance many theories and frameworks can be leveraged. Two very well-known resources for such frameworks are the Data Governance Institute [opens in new tab] and DAMA International [opens in new tab].
Khatri and Brown (2010) proposed five data governance decision domains: data principles, data quality, metadata, data access, and data lifecycle.
Whilst many of the data governance frameworks being created for business today have commonly ten or so focus areas, Khatri and Brown’s (2010) Decision Domains is a simpler model that comprehensively covers the subject areas of the more complex models. These are outlined in Figure 6.

Source: Adapted from decision domain model by Khatri and Brown (2010). [Go to image description]
Data governance principles should assist healthcare organisations in the same jurisdictions to improve efficiency and reduce data analysis costs, as well as enhancing data quality and standardising data formats (Reddy et al., 2022). In addition to enabling analysis, they should also help to facilitate integration into software used across the same organisations (Reddy et al., 2022).
Data Storage and Retention
Effective data storage, capture, transformation, visualisation, and architecture requires reliable access to storage. Data storage options include hard drives (local to a PC, portable or server-based), cloud storage (someone else’s hard drive), USB sticks, CD/DVDs, mobile phones, among others. In health USB sticks and other portable media are not recommended due to potential for security breaches. Data types can be structured (e.g., data entered into structured forms) or unstructured (e.g., digitally scanned handwritten notes, voice recordings, videos, or photos). Structured and unstructured data may be stored in file storage (directory-based, accessed by paths), block storage (location-based, accessed by an ID), or object storage (typically for unstructured data, accessed via HTTP). The Table below outlines considerations around choosing appropriate storage types.
Maintaining good data storage practices not only protects data and reduces costs, but also enables researchers to justify and verify research outcomes, maximise future research potential, and minimise resource waste (NHMRC, 2019).
Standards
Adhering to established standards ensures that data are findable, accessible, interoperable, and reusable (NHMRC, 2019). Creating clear guidelines for naming and storage locations simplifies the process of locating the necessary data. Policies concerning ownership and control ensure that modifications and additions to, or removals from datasets are approved, facilitating the use of the data by others (NHMRC, 2019). Data integrity policies ensure that existing data are not altered and that any augmentations maintain the integrity of the original data.
Scalability
Healthcare data storage faces the challenge of rapidly increasing volumes from video, photography, and real-time monitoring (Villa, 2021). On-premise storage involves maintaining servers at healthcare facilities, and is generally not highly scalable due to the capital outlay required. However, if configured well, this can provide fast access to data. Edge data centres reduce latency by bringing data centres close to the source (Zeydan et al., 2024), and tend to be more scalable as there is no capital outlay. However, edge data centres are more costly than cloud solutions. Scalable storage solutions include cloud storage or hybrid options; however, lower cost storage may incur higher costs for access. Balancing volume, accessibility and speed is crucial in storage architecture decisions. Tools such as Databricks, BigQuery, data warehouses, data lakes, and Elasticsearch manage and make medical data searchable via metadata or tags (Zeydan et al., 2024).
Australia’s data sovereignty laws, while not as comprehensive as the EU’s GDPR, require certain types of data to be stored within Australian borders and mandate specific protections for personal information under the Privacy Act 1988. The United States, has a more sectoral approach to data protection, Australia shares some similarities with Europe’s data protection framework, though it generally maintains less stringent requirements and enforcement mechanisms.
Timeliness
Timeliness refers to how quickly data can be accessed after it is entered. Timely does not necessarily mean immediate, timing is relevant to its intended purpose (Australian Institute of Health and Welfare, 2018). When gathering large amounts of real-time data, it is essential to consider optimising storage. In some cases, keeping (for example) the most recent hour of data and then aggregating data every other hour may be more efficient. Only data essential for clinical care, subject to retention laws, computation, viewing or for analysis and reporting should be retained. When dealing with real-time data the speed of read and write operations is critical and consideration should be given to the computation power available for both data access and computation. The system must be well-planned with the right processing capacity and storage accessibility (Zeydan et al., 2024). Optimised data storage options such as AVRO, Parquet, and Pbuffer can increase performance when writing to or retrieving large volumes of near real-time data from storage for analysis (Zeydan et al., 2024).
Archival and Retention Requirements
Data retention is essential for lifecycle management, ensuring organisations maintain necessary information, comply with legal requirements, and optimise storage through clear policies, structured schedules, and regular audits (Ige et al., 2024). Retention decisions involve determining whether to keep, archive, or destroy data, and how long it should be retained.
Establishing comprehensive retention policies provides a structured framework for consistent and legal data management, preventing unnecessary storage costs and legal non-compliance (Ige et al., 2024). These policies must consider legal and regulatory requirements, such as Australian privacy laws and guidelines from governing bodies like PHNs, Medicare, Private Health Insurers, and AHPRA.
Business needs also play a role in data retention. Some data may be valuable for strategic planning or improving medical outcomes, such as retaining 20 years of data for researching health outcomes of babies born with cerebral palsy. It is important to determine the appropriate level of detail for retained data.
Organisations implement retention schedules by classifying data, setting retention periods based on legal and business needs, and using technical controls to automate data deletion or archiving. Regular audits and reviews ensure compliance and adaptation to evolving regulations and business requirements, supported by data management tools that streamline the process and maintain policy adherence (Ige et al., 2024).
Collect, Capture and Create
“Collect, capture and create” refers to the process of entering data into systems of medical records, or temporary systems (e.g., surveys entered into an Excel spreadsheet) and collecting data from them. There has been an “explosion” in the volumes of health data generated and stored. Data sources include electronic health and medical records, medical imaging, genomics, sensors, and mobile-based health apps (Reddy, 2023). This growth continues exponentially through advancements in technology supporting healthcare. Read further about data sources in these chapters Electronic Medical and Health Records and Beyond the Health Record: Alternative Sources of Healthcare Data
Availability
If healthcare data are not available in a timely manner, it can be the difference between life and death for a patient. Data should exist, be stored in an accessible manner, and able to be restored if lost or damaged. The figure below lists key considerations for making data available.
There are constraints to available data in healthcare and include cost, privacy, fragmented patient care, and human resources (Chen et al., 2020). Down-time procedures, redundancy, and backup systems are therefore essential to protect against system failures and ensure data availability. The Box below constraints to available data in healthcare.
Cost
Cloud storage and on-premise storage both come with considerable costs.
- Cloud storage costs increase with each retrieval, and multiple retrievals of each record during the process of analysis or tool interactions further elevate the costs.
- Factors impacting the cost of storage include the volume of retrievals and vendor pricing (Chen et al., 2020).
Fragmented Patient Care
Fragmented care applies in multiple situations, including:
- Patients seeing healthcare professionals from different organisations and jurisdictions.
- Hybrid platforms (a mixture of paper and digital systems) to record patient data during their inpatient stay, including transitions across sites (e.g., from one hospital department to another or from a hospital to a rehabilitation centre) (Chen et al., 2020; Pastorino et al., 2019).
- Lack of integration of software used by departments within the same organisation, leading to fragmented data entry, miscommunication, and fragmented care (Chen et al., 2020b; Tan et al., 2015).
Human Resources
- Finding suitably trained and affordable data engineers, analysts, and data scientists to manage all aspects of data can be challenging for any healthcare establishment, particularly for smaller and rural health organisations (Schaeffer et al., 2017). This can hinder the successful implementation of data analytics if not accounted for in workforce planning (Schaeffer et al., 2017; Chen et al., 2020).
Accessibility
For data to be accessible; systems need to be available, data needs to be managed in a way that it is readable (data management), users need to be granted access but to protect the data it needs to be controlled (access control and security) and the system needs to be useable (user experience).
Data Management
Data management is discussed in other sections of the chapter; however, in the accessibility context, it relates to easy identification of data elements. Well defined terms, good reference tables, metadata management standards, and data architecture are critical aspects of data management that help to ensure that data are accessible by others.
Data Privacy
Privacy refers to individuals or groups’ ability to seclude themselves or information about themselves and reveal them selectively (Sun et al, 2014). Privacy is a fundamental human right (OAIC, n.d). Personal health information is considered even more sensitive than most personally identifiable information, as it comes with significant risk to individuals if exposed has more stringent protection requirements. (Owens et al., 2023). Therefore, access to data must comply with standards, principles, and regulations around data privacy. Core considerations in privacy decisions relate to the purpose for data use, whether permission has been obtained, whether use is ethical, and whether the use aligns with the reasons given to patients, research participants, staff and so forth. Copyright and intellectual property questions must also be addressed to ensure the right to store and use the data and compliance with policies for its correct use (NHMRC, 2019). These topics are covered in more detail in the chapters on Cybersecurity and Health Information Law, Privacy and Ethics.
Cyber Security
Cybersecurity is the process of detecting and protecting against data breaches. Due to the sensitivity of personal health data and the increasing sophistication of hackers, healthcare organisations must prevent data breaches by using up-to-date antivirus tools, multifactor authentication, and encryption (Chen et al., 2020; Reddy et al., 2022). The types of attacks that require defence include service abuse, where hackers acquire extra data, destroy data, or overload systems; and denial of service attacks, which hijack networks and disrupt access (Sun et al., 2014). Security is discussed in more detail in this chapter on Cybersecurity.
Identity and Access Management (IAM)
Strong IAM is crucial to preventing fraudulent activity. This is just as important for small research projects as large enterprises, who hold personal, financial and other information about its patients or customers.
Password management creates challenges for organisations, as users find regular changes difficult. Attempts to use other means to ensure they can remember their passwords can create more risk than not having regular password changes would create (Glöckler et al, 2023). Multi-factor authentication enables organisations to reduce reliance on passwords alone and enables the ability to use facial, fingerprint, or voice identification from mobile devices.
Fraud management requires separation of duties, which is often used to ensure that only some of the steps of a critical operation are performed by one person. (Glöckler et al, 2023). Auditing is another aspect of identity and access management designed around fraud identification. Certain levels of auditing in systems are required by law and some by necessity. Data privacy breaches often require the need to trace back through audit logs to identify who did what and how. More proactive approaches to auditing may also include exceptions monitoring through AI to identify breaches that may not be distinguishable or go unreported.
Sharing across jurisdictions
Sharing healthcare data across jurisdictions is challenging due to privacy regulations and the difficulty of identifying individuals across different jurisdictions. Despite the benefits of data sharing for healthcare outcomes, particularly for rare diseases, stringent regulations often protect such data. The Australian Government has introduced measures to facilitate data sharing across organisations, including the Data Availability and Transparency Act 2022, which establishes a best practice scheme for sharing Australian Government data to increase availability (Office of the National Data Commissioner, 2023). This Act should be considered when sharing public health data between networks.
Architecture
Data architecture describes how a system should be set up to enable quick access to insights from data. There are centralised and decentralised architectures and the choices made around this influence data literacy and data governance. Decentralised architecture enable data literacy, but are harder to govern. Centralised architecture is easier to govern, but reduces flexibility and freedom of accessing the data.
Principles of data architecture relate to interoperability, infrastructure, and enablement of data quality, and these can be researched further at DAMA [opens in new tab] using the Data Management Body of Knowledge. Architecture around the storage and flow of data was discussed in the data storage section. Infrastructures for data for accessibility can include Data-Warehouse, Data-Lake, Data-Vault, Lambda, Kappa, IOT-a, Microservices, and Zeta among others (Behera & Kalipe, 2023). Further reading on these systems is available in this paper by Behera and Kalipe (2023) [opens in new tab].
Data Management
In the architecture context, data management refers to the standards and engineering of the data, the lineage approach, and the way that the data are engineered for reporting, the way that the data assets are classified and documented, and decisions regarding approaches to connectivity. It also covers aspects of data quality management.
Interoperability
In this context, interoperability is the ability for systems to share information. There are three types of interoperability: technical interoperability, information interoperability, and operational or business interoperability (Owens et al., 2023), as defined in the Box below.
Foundational and Structural or Technical Interoperability is enabled through the use of agreed data exchange specifications to ensure consistency in data structure and format, simplifying system interactions and integrations. (AIHW 2018)
Information or Semantic Interoperability is defined as the capability of two or more systems to communicate and exchange information, for each system to interpret the meaning of received information, and to use it seamlessly with other data held by that system. (AIHW 2018)
Organisational or Business Interoperability is how business processes are shared impacts greatly the ability for data to be shared. Interoperable processes makes it possible for the systems to interact or teams to share data. Different processes with seemingly the same data may in fact require translation to be interoperable (Owen et al., 2023).
All of the types of interoperability in the Box above are important to healthcare. Technical interoperability, however, is critical to enable the sharing of information in such a way that systems across jurisdictions can understand it (Owens et al., 2023). Formats such as HL7 and SNOMED are important to this. Interoperability is discussed further in chapters on Electronic Medical and Health Records and Navigating the Future: The Impact of Health Informatics and Digital Technologies on Healthcare.
Accuracy
Maintaining data quality is crucial for any information system, as ensuring protection against unauthorised deletion, modification, or fabrication ensures the accuracy of the data. (Sun et al, 2014). The complexity in healthcare arises due to clinician workloads, poor user experience design in healthcare applications, volume of processes, and the individuals involved in data entry (Owen et al.,2023). Data quality management areas are listed in the Figure below and discussed in the following sections.
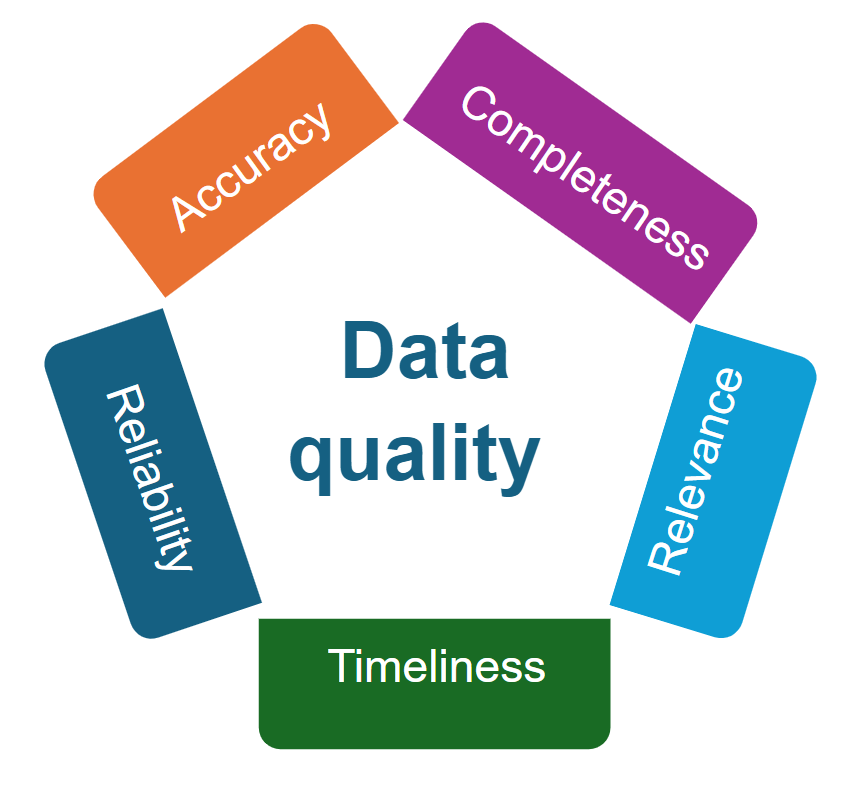
Accuracy and Completeness
Accuracy refers to the correctness of information, while completeness ensures that all necessary information is included. Data gaps can arise for various reasons, including missing data and missing knowledge (Australian Institute of Health and Welfare, 2018). Several stages in the data management lifecycle can affect accuracy and completeness, as shown in the Table below.
| Collection |
|
|---|---|
| Storage |
|
| Integration |
|
| Analysis |
|
| Visualisation |
|
| Archival |
|
Reliability, Relevance, and Timeliness
It is important to recognise that trust plays a significant role in ensuring people use data to help inform decisions. Poor quality data will certainly erode trust. Identifying where in the lifecycle the issues arise and addressing them will enhance trust in the data. It is also important that the data are consistently available, current, complete, and suitable for the particular analysis. Matters of timeliness may include how frequently the data is updated (i.e., when analysing the current challenges for an emergency department, previous week’s data may not be relevant, or timely).
Data remediation to achieve good quality data brings its challenges availability of clinicians to correct data entry issues is a key one. Data fixes of clinical data are not easily passed to an administrator who has no knowledge of the clinical context. It often requires the knowledge of the specific clinician that entered that data. There are several places that data can be remediated and these are listed with a description in the Table below. Identifying data quality issues ordinarily requires a set of rules that are run over the data and a report generated from this (or through patient complaint). The advancement of AI may mean better data quality reporting can be achieved through more AI driven exceptions management that provides a list of anomalies.
| Option | Description |
|---|---|
| Cleanse at source | This involves ensuring that any data that needs correcting is corrected in the user interface of the applicable system. It is the best approach for ensuring the data is trustworthy as the reporting and operating systems will show the same information. It is also the most difficult to achieve. |
| Cleanse in data storage | Using rules to edit the data in the database to ensure accuracy. This can be ideal for reference data that is not in the main source system, but changing other data in this way will mean that data is not the same in the user interface as it is in the reporting interfaces. This is a risk although as it can be automated the process is more repeatable. |
| Cleanse in data extract | This involves cleansing the data once it is extracted. It is the easiest to achieve but it is often not a repeatable process, and the data once used in reporting systems is different from both the data in the operating system and the storage system. It is the least desirable approach to data cleansing and carries risk of low trust in its outputs. |
Implications of bad quality data can have system-wide impacts; for example, incorrect or incomplete maternity data being submitted to the National Perinatal Data Collection could result in incomplete or incorrect research outcomes.
Activity
Want to know more? Read the chapters from this text on Data Analytics for Public Policy and Management
Ability
There are several areas to consider regarding ability or capability, such as technical skills, data analysis, critical thinking skills, communication, and collaboration.
Technical Skills
Technical skills include proficiency in using data analysis tools and software, knowledge of statistical methods and principles, data management skills, and data governance skills, including privacy and ethics principles.
These skills often require many years of practical experience, and it will be challenging to find one person with all of these skills. Creating systems for collaboration that will connect people with more advanced technical skills to those that have the more advanced domain knowledge will enable greater ability to gain insights.
Analytical and Critical Thinking, Communication, and Collaboration
Analytical and critical thinking skills include data literacy, critical thinking, problem solving skills, and, most important, depth of understanding of the subject at hand (domain knowledge), the Oxford English Dictionary (n.d.) describes critical thinking as “The objective, systematic, and rational analysis and evaluation of factual evidence in order to form a judgement on a subject, issue, etc.” . Problem solving is the ability to find a solution to a problem, which would no doubt involve critical thinking. Domain knowledge is the understanding of the field in which you are researching, studying, or working. Communication and collaboration involve sharing knowledge and working together, acknowledging that others can contribute valuable insights to the analysis. Effective communication involves using the results of your analysis to shape other people’s thoughts and beliefs. As data literacy encompasses these skills, further explanation of this is provided below.
Data Literacy
According to Hassan (2014) “Data literacy is the ability to ask and answer real-world questions from large and small data sets through an inquiry process, with consideration of ethical use of data. It is based on core practical and creative skills, with the ability to extend knowledge of specialist data handling skills according to goals. These include the abilities to select, clean, analyse, visualise, critique and interpret data, as well as to communicate stories from data and to use data as part of a design process”.
Several best practices for teaching data literacy have been identified, including workshops and labs that provide practical experience and allow students to refine their skills through trial and error. Module-based learning allows students to build on previously learned skills in a systematic way, fostering confidence and deeper understanding (Wuetherick et al., 2016). Lastly, using real-world data in project-based learning helps develop technical and critical thinking skills (Wuetherick et al., 2016). Core subject areas are depicted in the Table below.
| Skills | Description |
|---|---|
| Research | Developing and proving a hypothesis are essential skills for analysis. |
| Data Privacy and Ethics | It is essential that all people that leverage healthcare data for analysis should understand the sensitivity of the data they use, the ethics around using and the laws that govern it’s use |
| Data Management | All people that analyse data need to practice data management so leveraging the standards and practices that exist mean that the data and analysis is re-usable |
| Data Analysis | Understanding the process of data analysis is a time saver for any data analyst and creates repeatability |
| Data Visualisation and Storytelling | The ability to identify the problem, articulate the solution and move hearts and minds to achieve an outcome all by leveraging data as evidence is a great skill to attain. |
Effective instruction in data literacy requires partnerships between educators, organisations willing to share data, and access to data processing technologies (Wuetherick et al., 2016). An ideal curriculum includes progressively challenging modules with hands-on learning and real data to foster critical thinking skills (Wuetherick et al., 2016).
The NHMRC (2019) code outlines responsibilities for research grants through NHMRC Section R4, which expects organisations to provide ongoing training and education that promotes and supports responsible research conduct for all researchers and those in other relevant roles. A data literate workforce requires that when clinicians and other healthcare stakeholders use graphical visualisations (pie charts, bar charts, line charts etc), they will be able to use critical thinking to evaluate whether the information presented is adequate and reliable, or whether more data is required to make more informed decisions. Without data literacy, they may accept biased interpretations as facts, leading to inaccurate knowledge, or worse, poor decisions (Hassan 2014).
Analysis
Data analytics involves using various techniques to analyse datasets and discover patterns, trends, correlations, and other valuable insights that can inform healthcare decision-making at both the patient and population levels. The advent of machine learning and AI has significantly enhanced the capacity to interpret complex health data (Reddy, 2023).
Analysis typically begins with a real-world hypothesis or a business/medical issue that needs to be addressed. Relevant data elements are then collected to support or refute the hypothesis. This process involves understanding the problem, gathering and examining data from different perspectives to avoid bias, applying critical thinking to evaluate the information, and then presenting the findings.
Cross-Industry Standard Process for Data Mining (CRISP-DM)
There are established methodologies for data mining, including CRISP-DM. Developed in the late 1990s, CRISP-DM has become widely used across various industries, including healthcare (Martinez-Plumed et al., 2021). However, the term “data mining” has become outdated and “data science” is now the preferred term (Martinez-Plumed et al., 2021). Through her extensive cross-industry experience in data and analytics, the author of this chapter finds this process particularly useful. There are six phases of data mining (Wirth and Hipp, 1999), as shown in Figure 8 below.
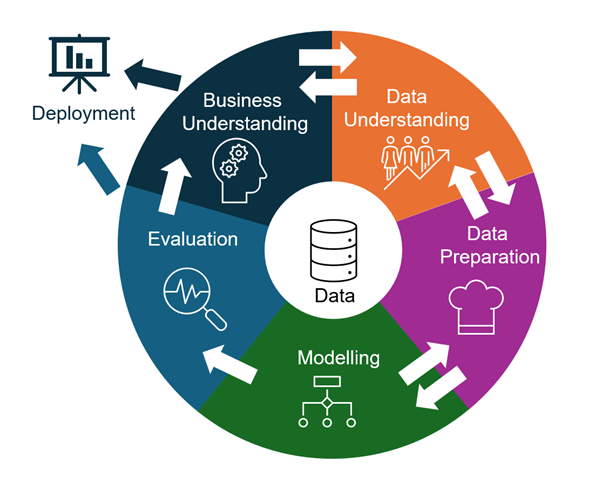
Source: Adapted from Figure 2 in Wirth and Hipp (1999).
Value to Healthcare
The integration of data analytics into health informatics is transforming healthcare. It allows healthcare providers to deliver improved patient care, boosts operational efficiency, accelerates medical research, and enhances public health monitoring (Reddy, 2023). Utilising data analytics in healthcare enables the full use of data from various sources. Using a data science approach for data analysis helps identify trends and develop more accurate diagnoses and treatments at higher quality and lower cost, leading to better patient outcomes (Raghupathi & Raghupathi, 2014). Predictive modelling helps identify preventive treatments, avoid medication misuse, find efficiencies, generate new revenue, and detect fraud (Raghupathi & Raghupathi, 2014).
Visualisation
Traditional data visualisation commonly includes standardised charts (such as bar, line, and pie charts) on dashboards. This approach is primarily analysis-oriented and it can be difficult to quickly grasp the intent of the display, limiting its communicative value (Zhang et al., 2022). In contrast, visual data storytelling employs a narrative-oriented process that emphasises clear, audience-specific communication with a goal of rapid understanding (Zhang et al., 2022).
Modern communication is highly visual, requiring an understanding of the audience to effectively convey messages (Zhang et al., 2022). Visual data storytelling presents information in graphic forms that the audience can easily understand (Zhang et al., 2022). This method may differ from traditional graphing rules, focusing on titles that convey clear messages and imagery that highlights key points and provides context. Simplicity is crucial for rapid understanding.
The first step in visual data storytelling involves identifying the message you want to convey, which is often quite complex. Often what needs to be conveyed relates to a problem that requires solving and it is essential that the extent of the problem is fully understood. Problem definition frameworks can provide significant value. Conveying the solution also takes work. Both working out the problem and the solution is often best with teamwork and collaboration. Conveying a clear message requires data and critical thinking, often drawn from insights from others. (Zhang et al., 2022). Creating visualisations that effectively convey this message requires an understanding of the audience, how they think, and what drives them. The author then uses their data knowledge to craft key information into a compelling narrative (Zhang et al., 2022).
Courses on data visualisation and storytelling provide tools for understanding the audience, business drivers, problem definition, and using data to address business needs. They demonstrate how to effectively identify and communicate key points to the intended audience.
Data Visualisation: From Understanding to Deployment
The process of data visualisation follows a structured yet iterative path through five key phases. Each phase builds upon the previous one, though there is often movement back and forth as new insights emerge.
The process begins with two interconnected phases of understanding. The first focuses on business requirements and problem definition, while the second examines available data sources. These phases work in tandem, with discoveries in one area often informing and reshaping understanding in the other. This dynamic interplay helps ensure that the final visualisation will effectively address the business need.
Data preparation follows as the third phase. This critical stage involves organising and cleansing the data, potentially merging multiple datasets, and formatting everything appropriately for analysis. Without thorough preparation, subsequent analysis may prove unreliable or misleading.
The modelling phase employs various analytical techniques, ranging from descriptive analytics that illuminate past events to predictive analytics that forecast future trends. Analysts might utilise familiar tools such as Excel and Power BI, or more specialised options like Python and R, depending on the complexity required. In healthcare settings, for instance, these tools might analyse clinician performance or predict hospital readmission rates.
During the evaluation phase, analysts apply critical thinking to assess their findings. This involves consulting with colleagues, reviewing previous research, and carefully considering any limitations or assumptions in their work. This reflective stage ensures the robustness of the analysis and identifies any additional factors that should be considered.
The final deployment phase transforms insights into compelling visualisations that tell a clear story. Whether feeding into other models or presenting to stakeholders, the key objective is to make the information accessible and actionable.
Throughout this process, effective data visualisation serves as a crucial tool for understanding, analysing, and communicating findings at each stage. The success of the final visualisation often depends on how well each phase has been executed and how effectively the iterations between phases have been managed.
Activity
Visit the Information is Beautiful blog [opens in new tab] and note 3 helpful ways that data can be visualised.
The phases that are required for visualising data starting with understanding the problem or challenge at hand. The text boxes below show these phases.
Phase 1 Business Understanding and Data Understanding
During these phases, the focus is on the problem and requirements from a business perspective (Wirth et al., 1999). The business problem is clarified, and a hypothesis is formulated. Data that could support or refute the hypothesis is sought. This process involves a back-and-forth exchange between understanding the data and comprehending the business problem, which continues until all data requirements are identified. These steps are revisited as the understanding of the data and outcomes evolves.
Phase 2 Data Preparation
The data preparation phase is designed to ready the data for input into modelling tools (Wirth et al., 1999). This phase involves activities such as data cleansing, data augmentation (combining with other datasets and reference data), and formatting the data for modelling tools (Wirth et al., 1999).
Phase 3 Modelling
During this phase, various modelling techniques are selected and tested to find the most accurate models. Often, multiple models are applied to address the same problem (Wirth et al., 1999). As results emerge, there’s a continual exchange with other phases to refine outcomes and generate new hypotheses.
Common modelling types include descriptive analytics (“what happened”), diagnostic analytics (“why something happened”), predictive analytics (“what could happen”), and prescriptive analytics (“what should happen”). Other techniques include regression, cohort, cluster, time-series, and text analysis. Effective application of these techniques is crucial for successful analysis (Houser et al., 2023). Analysts use tools like Microsoft Excel, Power BI, Flourish, Qlik, SAS, or Jupyter Notebook, along with languages such as SQL, R, Python, or DAX, for advanced queries and calculations (Houser et al., 2023). For health informatics (HI) professionals, these techniques and technologies have numerous applications in healthcare data. Descriptive analytics is often used for reporting, Qlik for physician performance analysis, and Power BI for predictive analytics, population health management, and hospital readmission analysis and prevention (Houser et al., 2023).
Phase 4 Evaluation
At this stage you leverage the outputs from the modelling phase and using critical thinking make your judgements as to its accuracy and application. You may likely consult with others and with previous research. Additionally reviewing previous steps to ensure you have thought of everything, understanding limitations and assumptions. A key objective in this stage is also to identify if there are other considerations that should be included (Wirth et al., 1999).
Phase 5 Deployment
Once knowledge has been gained it needs to be organised and presented in a way that it is useful, either for feeding back into other models, or for presenting to tell a story.
Key Implications for Practice
The effective management of health data relies on the ‘5 A’s’ framework: Availability, Accessibility, Accuracy, Analysis and Ability. For health information practice to succeed, data must not only exist and be stored accessibly, but systems must ensure its availability through robust backup procedures and redundancy measures. Additionally, proper access controls and security protocols must protect sensitive health information while still enabling authorised users to retrieve it efficiently.
Data quality is paramount to use of data in health care. Data quality requires rigorous attention to accuracy, completeness, reliability and timeliness throughout the data lifecycle. Health information practitioners must implement strong data governance frameworks that clearly define roles, responsibilities and standards for data management. This includes establishing clear processes for data collection, storage, analysis and disposal, while ensuring compliance with privacy regulations and maintaining data integrity across jurisdictions.
The human element is always crucial – successful health information practice around data and data use requires both technical competency and data literacy among practitioners. This encompasses analytical and critical thinking skills, domain knowledge of healthcare, and the ability to effectively visualise and communicate insights from data. As healthcare generates increasingly vast amounts of data through electronic health records, imaging, genomics and wearable devices, practitioners must be able to leverage modern analytical tools and techniques while maintaining ethical standards and patient privacy. Ongoing training and education in data literacy should be prioritised to build these essential capabilities across the healthcare workforce.
References
Alowais, S. A., Alghamdi, S. S., Alsuhebany, N., Alqahtani, T., Alshaya, A. I., Almohareb, S. N., Aldairem, A., Alrashed, M., Bin Saleh, K., Badreldin, H. A., Al Yami, M. S., Al Harbi, S., & Albekairy, A. M. (2023). Revolutionizing healthcare: The role of artificial intelligence in clinical practice. BMC Medical Education, 23(1), 689. https://doi.org/10.1186/s12909-023-04698-z
Australian Institute of Health and Welfare. (2018). Chapter 10: Data Management in Australia’s Health 2018. In Australia’s Health 2018 (pp. [specific pages]). https://www.aihw.gov.au/getmedia/6d6f08b4-15e6-4b58-bb62-76b9e9e4cc4f/aihw-aus-240_chapter_10.pdf.aspx
Ball, A. (2012). Review of Data Management Lifecycle Models (version 1.0). REDm-MED Project Document redm1rep120110ab10. University of Bath. https://m.moam.info/review-of-data-management-lifecycle-models-university-of-bath-opus_6479d274097c476b028bb4da.html
Behera, R. K., & Kalipe, G. K. (2023). Big data architectures: A detailed and application-oriented review. ResearchGate. https://doi.org/10.1007/s12599-023-00830-x
Chen, J., Pastorino, R., & Reddy, S. (2020). Barriers to data analytics in healthcare. In Value-based Healthcare. OER Collective. https://oercollective.caul.edu.au/value-based-health-care/chapter/5-6-barriers-to-data-analytics-in-healthcare/
Clark, A. (2018). The machine learning audit—CRISP-DM framework. ISACA Journal, 1(1), 1-10. https://www.isaca.org/-/media/files/isacadp/project/isaca/articles/journal/2018/volume-1/the-machine-learning-audit-crisp-dm-framework_joa_eng_0118.pdf
Glöckler, J., Sedlmeir, J., Frank, M., & Fridgen, G. (2023). A systematic review of identity and access management requirements in enterprises and potential contributions of self-sovereign identity. Business & Information Systems Engineering: International Journal of WIRTSCHAFTSINFORMATIK, 66, 421–440. https://doi.org/10.1007/s12599-023-00830-x
Harvard University. (n.d.). Biomedical Data Lifecycle. https://datamanagement.hms.harvard.edu/plan-design/biomedical-data-lifecycle
Hasan, H. (2014). Learning analytics and socio-technical system design: Insights from Jane Jacobs. Journal of Community Informatics, 10(3). https://openjournals.uwaterloo.ca/index.php/JoCI/article/view/3275/4298
Houser, S. H., & Blabac, L. (2023). Data Analytics Concepts for Health Information Professionals. Journal of AHIMA. https://journal.ahima.org/page/data-analytics-concepts-for-health-information-professionals
Ige, A. B., Chukwurah, N., Idemudia, C., & Adebayo, V. I. (2024). Managing data lifecycle effectively: Best practices for data retention and archival processes. International Journal of Engineering Research and Development, 20(7), 453-461. https://www.researchgate.net/profile/Naomi-Chukwurah-3/publication/388387603_Managing_Data_Lifecycle_Effectively_Best_Practices_for_Data_Retention_and_Archival_Processes/links/6795c951645ef274a44140c1/Managing-Data-Lifecycle-Effectively-Best-Practices-for-Data-Retention-and-Archival-Processes.pdf
Khatri, V., & Brown, C. V. (2010). Designing data governance. Communications of the ACM, 53(1), 148-152. https://doi.org/10.1145/1629175.1629210
Kington, M. (2003, March 28). Knowledge is knowing that a tomato is a fruit; wisdom is not putting it in a fruit salad. The Independent. https://www.independent.co.uk/voices/columnists/miles-kington/heading-for-a-sticky-end-112674.html
Martínez-Plumed, F., García-Galán, S., Ribelles, N., Chulvi, B., Hernández-Orallo, J., Gómez-Martín, M. Á., & Ferri, C. (2021). CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories. IEEE Transactions on Knowledge and Data Engineering, 33(8), 3048-3061. https://doi.org/10.1109/TKDE.2019.2962680
Monash University. (n.d.). DHMSC Short Course 3: Good Practice in Digital Health. Monash University Professional Development.
Miller, K., Miller, M., Moran, M., & Dai, B. (2018). Data Management Life Cycle, Final report. PRC 17-84 F. Texas A&M Transportation Institute. https://static.tti.tamu.edu/tti.tamu.edu/documents/PRC-17-84-F.pdf
National Health and Medical Research Council (NHMRC). (2019). Management of Data and Information in Research: A guide supporting the Australian Code for the Responsible Conduct of Research. Commonwealth of Australia. ISBN Online: 978-1-86496-033-4.
Nayak, R., & Puri, R. (2021). Big data analytics in healthcare: Methods, practices, and future directions. Journal of Big Data, 8(1), 81. Retrieved from https://link.springer.com/article/10.1186/s40537-021-00481-3.
Office of the National Data Commissioner. (2023). Introducing the DATA Scheme. https://www.datacommissioner.gov.au/sites/default/files/2023-04/Introducing%20the%20DATA%20Scheme%20-%20April%202023.pdf
Office of the Australian Information Commissioner. (n.d.). What is privacy? https://www.oaic.gov.au/privacy/your-privacy-rights/your-personal-information/what-is-privacy
Owens, S., Fojtik, R., Braga, B., & Raghunathan, K. (2023). Chapter 6. In H. Almond & C. Mather (Eds.), Digital Health: A Transformative Approach (pp. 104-140). Elsevier Health Sciences.
Oxford English Dictionary. (n.d.). Critical thinking. Retrieved February 1, 2025, from https://www.oed.com/dictionary/critical-thinking_n?tab=factsheet#1244228750100
Raghupathi, W., & Raghupathi, V. (2014). Big data analytics in healthcare: Promise and potential. Health Information Science and Systems, 2(3). http://www.hissjournal.com/content/2/1/3
Reddy, S. (2023). The Growing Importance of Data Analytics in Health Informatics. HIMSS Resource Center. https://gkc.himss.org/resources/growing-importance-data-analytics-health-informatics
Reddy, R. C., Bhattacharjee, B., Mishra, D. et al. (2022). A systematic literature review towards a conceptual framework for enablers and barriers of an enterprise data science strategy. Information Systems and e-Business Management, 20, 223–255. https://doi.org/10.1007/s10257-022-00550-x
Sun, Y., Zhang, J., Xiong, Y., & Zhu, G. (2014). Data security and privacy in cloud computing. International Journal of Distributed Sensor Networks, 2014, 190903. https://doi.org/10.1155/2014/190903
Villa, D. (2021). Addressing the data storage challenges in healthcare. Open Access Government. [Open Access Government] https://www.openaccessgovernment.org/addressing-the-data-storage-challenges-in-healthcare/115033
Wirth, R., Hipp, J. (1999). CRISP-DM: Towards a Standard Process Model for Data Mining. http://www.cs.unibo.it/~danilo.montesi/CBD/Beatriz/10.1.1.198.5133.pdf
Wuetherick, B., Ridsdale, C., Bliemel, M., Matwin, S., Rothwell, J., Irvine, D., Smit, M., Ali-Hassan, H., & Kelley, D. (2016). Data literacy: A multidisciplinary synthesis of the literature. https://www.researchgate.net/profile/Brad-Wuetherick/publication/332973704_Data_Literacy_A_Multidisciplinary_Synthesis_of_the_Literature/links/5cd46e31299bf14d95851be9/Data-Literacy-A-Multidisciplinary-Synthesis-of-the-Literature.pdf
Zeleny, M. (1987). Management support systems: Towards integrated knowledge management. Human Systems Management, 7(1), 59-70. https://doi.org/10.3233/HSM-1987-7108
Zeydan, E., Arslan, S. S., & Liyanage, M. (2024). Managing distributed machine learning lifecycle for healthcare data in the cloud. IEEE Access, 12, 115750-115774. https://doi.org/10.1109/ACCESS.2024.3443520
Zhang, Y., Reynolds, M., Lugmayr, A., Damjanov, K., & Hassan, G. M. (2022). A Visual Data Storytelling Framework. Informatics, 9(4), 73. https://doi.org/10.3390/informatics9040073
Image descriptions
Figure 1: An infographic titled “Expanding role of data and AI in clinical practice.” It features a horizontal blue arrow, labeled “Data and AI,” pointing to the right.
Four key sections border the arrow:
- Clinical practice: Data to inform diagnosis, treatment and ongoing management; Patient survey and safety/quality metrics applied to improve care.
- Predictive and prescriptive analytics: Data for risk prediction, disease diagnosis; Treatment recommendations.
- Evidence based medicine: Data and information to inform practice, identify best practice treatments and guidelines; Research and genomics.
- Personalised medicine: Tailored treatments for individuals; Disease management for individuals and populations; Patient engagement with treatment; Mental health support with Large Language Models; Enhanced patient and community education.
Figure 2: The image is a horizontal infographic composed of five stacked, colourful bars, each representing a factor affecting data utilisation in healthcare. Each bar features a heading and a brief explanation.
- The topmost bar is labeled “Availability,” and states that if data doesn’t exist or isn’t stored, it won’t be available for analysis.
- The second bar is “Accessibility,” noting that low accessibility leads to its lack of use.
- The third bar, titled “Architecture,” explains that poorly structured data hinders the combination of data sets for analysis.
- The fourth bar is labeled “Ability,” indicating that poor data literacy and analytical skills reduce the use of data.
- The final bar is “Accuracy,” emphasising that poor data quality reduces trust and the willingness to use data.
Figure 3: The image is a circular diagram divided into four equal sections, each representing different aspects of data management.
Starting from the top left and moving clockwise, the sections are labeled as follows:
- Dark blue section labeled “Efficiency” lists key points: “Reuse data,” “Repeatable processes,” and “Easy to use tools.”
- Navy section labeled “Safety” highlights: “Privacy,” “Cyber,” “Accuracy,” and “Retention.”
- Purple section labeled “Trusted” includes: “Timeliness,” “Data quality,” and “Useful.”
- Green section labeled “Connectivity” contains: “Interoperability” and “Ease of access.”
Each segment focuses on a crucial aspect of data management, identified by specific descriptors within each coloured quadrant.
Figure 4: A diagram with five hexagons labeled “What,” “Where,” “How,” “If,” and “Can,” related to data management questions.
- What data you have? Details of what the data contains
- Where is it located?
- How to get it? Does the data exist what tools can you use to access it?
- If it’s accurate? Does it represent the hypothesis, is it true and is it leveraging good quality data?
- Can you use it? Are you allowed to use it? Is it ethical or legal?
Figure 5: The image is a circular diagram divided into six colored segments, each representing a different stage of the data lifecycle. At the centre is a smaller circle labeled “Data Governance Storage” surrounded with associated terms like “identity access management”, “standards”, “privacy”, “cyber” and “medical decision-making”. The cycle progresses in an anti-clockwise direction, beginning with the stage “Create, Collect and Capture” and leads into other stages in sequence: “Cleanse and Prepare”, “Analyse and Collaborate”, “Visualise and Evaluate”, “Share and Disseminate” and finally, “Archive and Retention”.
Each segment is associated with specific tasks and technologies.
Segment 1 – Create, Collect and Capture
- Patient administration systems
- Diagnostic systems
- Lab testing results
- Excel spreadsheets
Segment 2 – Cleanse and Prepare
- Data augmentation
- Format for modelling tools
Segment 3 – Analyse and Collaborate
- Version control
- Cross-industry standard process for data mining
- Artificial intelligence and machine learning
- SQL / R / Python / Dax
- Hypothesis driven
Segment 4 – Visualise and Evaluate
- Analysis oriented visualisation
- Audience awareness
- Narrative oriented visualisation
- Critical thinking
Segment 5 – Share and Disseminate
- Communication
- Storytelling
- Ethics
- Security conscious
- Interoperability and integrations
Segment 6 – Archive and Retention
- Retention schedules
- Legal requirements
- Retention policies
- Business requirements
- Needs per datatype
Figure 6: A diagram divided into five vertical columns, each labeled at the top with a different data governance domain and containing text explaining the specific domain it represents.
- Domain 1: Labeled “Meta Data Management” refers to aligning the business glossary, data definitions and data lineage with business processes. Having clearly aligned decision making around these.
- Domain 2: Labeled “Data Quality Management” refers to enabling data owners to make decisions that will enable the improvement of data quality in source systems. A practice of cleansing the data at source data quality rules management and AI driven data quality models.
- Domain 3: Labeled “Data Lifecycle Management” refers to ownership policies around data ingestion including authority to consume data, avoiding multiple versions of the same data multiple locations. Data retention and data disposal ownership and decision making.
- Domain 4: Labeled “Data Access” refers to principles of security and privacy are adhered to so that the right people are accessing the data and with the right permission to access it.
- Domain 5: Labeled “Data Principles” refers to appropriate standards in the data management lifecycle to enable interoperability and alignment. Data management teams standards to enable efficiency between teams preventing duplicate effort.
Data sovereignty refers to the concept that digital data is subject to the laws and governance of the country in which it is physically stored or processed. Simply stated, data that is stored and processed in the country where it was generated.
According to IBM [opens in new tab] "Avro is an open source project that provides data serialisation and data exchange services for Apache Hadoop. These services can be used together or independently. Avro facilitates the exchange of big data between programs written in any language."
According to IBM [opens in new tab] "Apache Parquet is an open source [opens in new tab] columnar storage format used to efficiently store, manage and analyse large datasets [opens in new tab]. Unlike row-based storage formats such as CSV or JSON, Parquet organises data in columns to improve query performance and reduce data storage costs".
