3 Large Language Models
By combining machine learning with vast datasets, we have developed foundation models that can perform various tasks. Since the publication of a paper on transformer architecture, many foundation models have appeared.[1]
 Foundation Models
Foundation Models
The Stanford University Centre for Research on Foundation Models define a foundation model as ‘any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks.’[2]
Foundation models are machine learning or deep learning models trained on extensive datasets encompassing text, images, code, and other forms of data from the Internet and various digital sources (sometimes referred to as large X models or LxM). What makes them foundational is their ability to serve as a base for multiple applications and tasks without requiring complete retraining.
These models can be adapted or ‘fine-tuned’ for specific purposes. Like a versatile foundation for a building that can support various structures, they provide a robust base of general knowledge and capabilities that can be specialised through techniques like fine-tuning or prompting.
Notable examples include Generative Pre-trained Transformers (GPT), Bidirectional Encoder Representations from Transformers (BERT), and other transformer-based architectures that have demonstrated remarkable capabilities in understanding and generating human-like text, translating languages, writing code, and creating images from text descriptions.
Large language models (LLMs) are a subset of foundation models focused on written text. Therefore, these models are trained on an exceptionally vast amount of textual data. LLMs specifically engage with language and are built on deep learning techniques to understand how characters, words, and sentences interact with each other. An LLM is a key technology that underpins the development of generative AI that generates realistic text.
 Explore
Explore
To learn more about foundation models and what it means for Australia, read the CSIRO’s ‘Artificial Intelligence Foundation Models Report’.
 Watch
Watch
Watch this short video that introduces LLMs.
Although LLMs show great potential for generating useful and creative text, they perform two separate tasks when producing outputs:
-
Assigning probabilities to every possible next word (or ‘token’, discussed below) given the prompt and everything it has already written.
-
Then choose one of those words and add it to the text. This step is called sampling.
The quality of text generation is mainly dependent on the choice of sampling methods and parameters.[3]
During training, a model learns parameters or weights. These are billions of numbers inside the neural network that it adjusts to capture patterns in data. Think of parameters or weights as the adjustable knobs and dials that the model tunes as it learns from data. Within LLMs, parameters typically manifest as numerical weights in the neural network that determine how different pieces of information should be processed and combined.
The number of weights in a model (often measured in billions for modern foundation models) indicates its complexity and capacity to learn patterns. For instance, GPT-3 has 175 billion parameters, while some newer models have even more. However, it’s important to note that while having more parameters generally allows a model to capture more complex patterns, it does not automatically guarantee better performance (just as having more piano keys doesn’t automatically make someone a better pianist). The quality of training data, model architecture, and training process is crucial in determining a model’s capabilities.
During text generation, sampling parameters are a user‑set of knobs (for example, temperature, top‑k or top‑p) that tell the already‑trained model how to turn its probability table into a final sequence of words.
Watch
There’s been a lot of talk lately about Generative Pre-trained Transformers (GPT) and LLMs. Watch this video from IBM that briefly explains what an LLM is and how it relates to foundation models. Then, it covers how they work and how they can be used to address various business problems.
Predicting what comes next…
To visually represent how LLMs generate text, take this example below. Based on the model’s training, it will sample the best word and append it to the sentence.
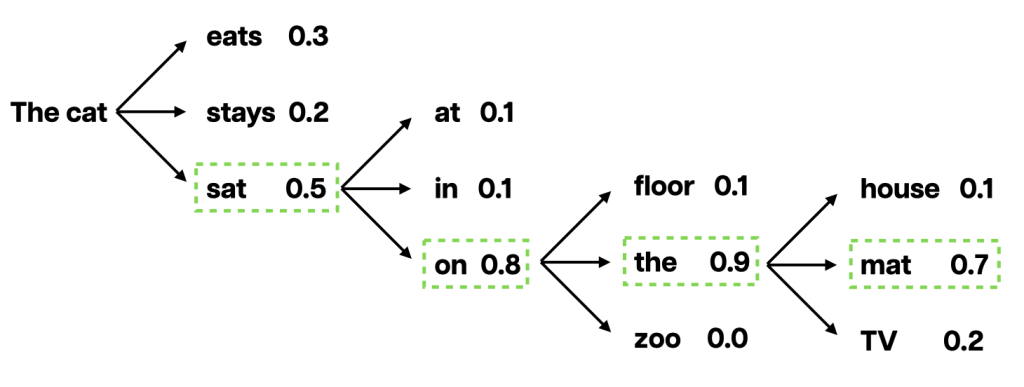
To give you an even better visual representation of the sampling process, follow the link below. The visualisations help show how sampling parameters can influence which word would be appended to the sentence. To use the tool, follow these steps:
- Use the dropdown box at the top of the page to select your desired sentence (there are 5 to choose from).
- The % probability of each token (or word) that would come next in the sentence appears as a bar graph, with the most probable appearing first.
- The blue squares underneath allow you to control sampling methods and hyperparameters. Select one (or more) by clicking the checkbox ☑️ at the top left-hand side of the box and adjusting the sliders to investigate their effect.
Click on the full-screen icon to explore the tool. To view it in a new browser window, follow this link.
 Do
Do
The hyperparameters and methods on the page are used to tune the output of LLMs, balancing creativity, coherence, and relevance in the generated text. They include:
- Temperature: Controls the randomness of the output. Adjusting the temperature parameter influences the randomness of the output. A ‘high temperature’ means a lower probability, resulting in more diverse and creative outputs. A ‘low temperature’ means a high likelihood, making results more predictable.
- Top K: A sampling method that limits the model’s next-token choices to the K most likely options. This helps reduce the chance of selecting low-probability tokens.
- Top P (nucleus sampling): A dynamic sampling method that selects from the smallest possible set of tokens whose cumulative probability exceeds a threshold P. This allows for more diversity than Top K while still avoiding unlikely tokens.
- Min P: A hyperparameter that sets a minimum probability threshold for token selection. Tokens below this threshold are excluded, helping to filter out very low-probability options.
- Top A: A sampling method that dynamically adjusts the sampling pool based on the probability distribution of tokens. It aims to strike a balance between diversity and quality in the generated text.
- Tail Free Z: A sampling method that truncates the ‘tail’ of the probability distribution, removing unlikely tokens while maintaining a natural distribution among the remaining choices.
- Typical P: A sampling method that selects tokens based on their typicality, favouring tokens with probabilities close to the mean of the distribution. This aims to produce more “typical” or representative text.
GPTs
GPTs (Generative Pre-trained Transformers) are a subtype of LLM that has fundamentally changed the landscape of natural language processing. These models utilise a sophisticated neural network architecture called a transformer, which was introduced in 2017.[4] They enable them to process and understand language by focusing on the relationships between words in a text, regardless of how far apart they might be.
The pre-trained aspect means these models learn general language patterns from large volumes of text data before being fine-tuned by humans. GPT’s generative nature makes it particularly powerful — it can produce human-like text by predicting the most probable next word in a sequence, enabling it to write essays, answer questions, summarise documents, and even write code. Each new iteration of GPT has become more capable, showcasing increasingly sophisticated abilities to comprehend context, follow instructions, and generate coherent, contextually appropriate responses across various topics and tasks.
Watch
Watch this short video where Martin Keen explains what transformers are.
Tokens
Large language models process text using tokens. Tokens are the fundamental units language models use to process and understand text. Essentially, it is how these models ‘read’ information. Think of tokens as the building blocks representing parts of words, whole words, or even punctuation marks. For example, the word ‘understanding’ might be broken into two tokens, ‘under’ and ‘standing’, while a simple word like ‘cat’ might be a single token. However, these models do not see the words in these tokens; instead, they see them as numbers. The tokens are seen as a long list of numbers called a “word vector.” Each vector represents a spot in an imaginary “word space”.[5] Think of it similar to coordinates on a map. Just like two cities being close together on a map, words with similar meaning are close together in this word space.[6]
Tokens are crucial because they determine how the model processes information and its operational limitations. The number of tokens a model can process in a single instance (often called the context window) determines how much text it can ‘see’ and work with at once, like having a bigger desk to spread out your work. This affects everything from the model’s ability to understand context in a conversation to the text length it can analyse or generate. The way text is split into tokens also impacts the model’s efficiency and ability to work across different languages, with some languages requiring more tokens to express the same meaning than others.
AI models like ChatGPT work by breaking down textual information into tokens roughly the size of three-quarters of an English word. For image-generating AI models like DALL-E, a token is a pixel of the image. For audio-based AI models like MusicLM, a token might represent a short sound segment.
For example, the following sentence comprises 116 characters, but is made up of 24 different tokens. The IDs of these tokens are [2500, 21872, 382, 448, 4994, 316, 28058, 1495, 17554, 162016, 350, 427, 6771, 11820, 20837, 8437, 8, 2338, 869, 7725, 2201, 1511, 20290, 13]. This is what the model would see.

Tokens and tokenisation came into sharp focus when users asked ChatGPT to count the number of ‘r’ characters in the word ‘strawberry’, which returned the answer ‘two characters’. For an LLM, the word comprises three tokens (see below). This error in character counting illustrates a key limitation of how these models process text through tokenisation. The IDs for these tokens would be [3504, 1134, 19772].

When the word “strawberry” is processed, the model does not see it as individual characters but rather as one or more tokens (depending on how its tokeniser was trained). While humans naturally perceive ‘strawberry’ as a sequence of individual letters containing three ‘r’ characters, the model processes it more holistically through its token representations. When asked to count specific characters, the model does not count in the traditional sense of the word. Instead, it makes a prediction based on its training data regarding the answer. The model is not performing the mechanical task of character counting, but instead attempts to generate what it thinks is the most probable answer based on its training.
Tokensier
You can estimate the number of tokens a message will use with OpenAI’s tokeniser tool.
Context Window
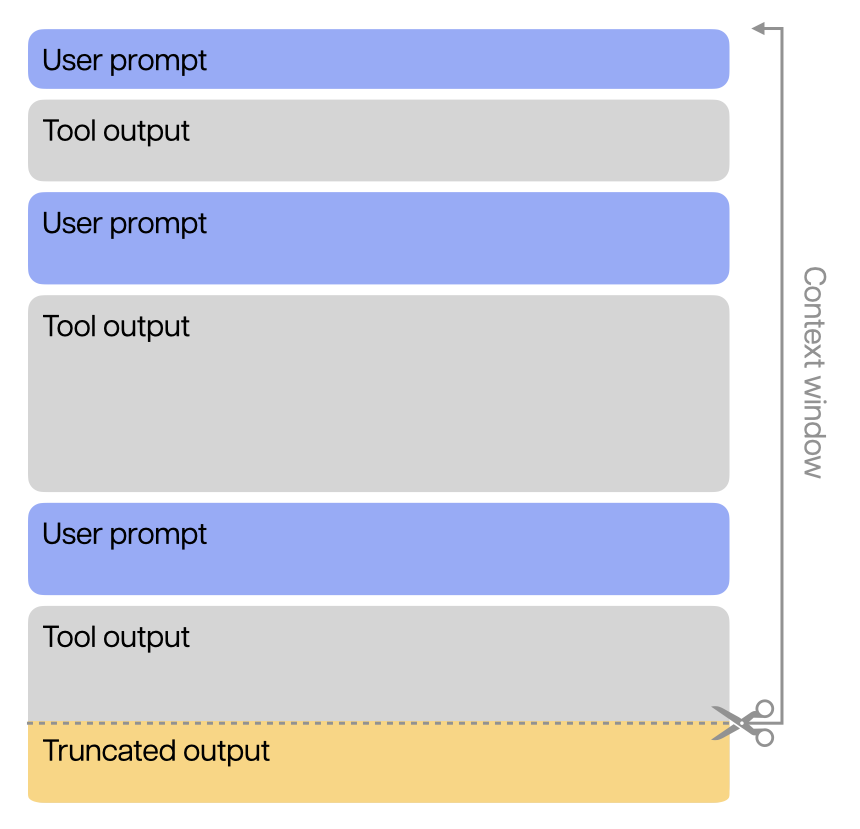
A model’s context window refers to the maximum number of tokens that can be used in a single request or interaction. The context window includes input tokens (text or data files uploaded with a prompt) and output tokens (tokens generated in response). For reasoning models (like OpenAI’s o1 and o3-mini), the context window includes reasoning tokens (used by the model to plan its response).
Ongoing dialogues with an LLM can include multiple inputs and outputs, which are part of the context window. This means that when a dialogue with an LLM exceeds the context window, subsequent responses generated may be truncated, or the model will begin to ‘forget’ earlier information. This can lead to mistakes and hallucinations. In some systems, users are often prompted to start a new chat window to avoid this outcome.
What’s going on under the Hood
Let’s now take each of the concepts and bring them together to see what happens when one of these generative AI chatbots generates a given word. Watch the following video, which provides a visual representation of how LLMs work under the hood and how data flows through them via transformers.
Tracing the thoughts of an LLM
Users are often amazed by their seemingly intuitive understanding of our questions and requests when we interact with language models like ChatGPT or Claude. But I am sure you have wondered what is actually happening when these AI systems process information and generate responses. AI models are trained and not directly programmed, so we do not exactly understand how they perform most of their tasks. However, Anthropic have introduced a new method to trace the thoughts of a language model.
Watch
Watch this video, which introduces the research and explains how it mapped the inner workings of LLMs.
Introduction to Neural Mechanisms in LLMs
Modern language models do not simply retrieve memorised answers or follow explicit rules coded by programmers. Instead, they develop their internal processes that enable them to reason through problems, plan effective responses, and transfer knowledge across various contexts.
Recent research has made significant progress in understanding these internal mechanisms. Just as biologists use microscopes to study cells, AI researchers at Anthropic have developed tools to peer inside language models and observe how they process information. This section explores some of these fascinating discoveries and what they reveal about how language models operate.
Before diving into specific examples and exploring the attribution graphs, let’s first establish some foundational concepts:
Features and Circuits
Language models contain millions or billions of interconnected artificial neurons. However, researchers have discovered that these neurons often work together in groups called “features” that recognise specific concepts. This could include anything from concrete objects, such as “dogs,” to abstract ideas, like “comparison” or “contradiction.”
These features are connected through “circuits” (i.e., pathways of information flow that perform specific functions). For example, one circuit might recognise when a math problem is being posed, while another might calculate the answer.
Step-by-Step Processing
When a language model reads your prompt, it does not immediately jump to the final answer. Instead, it often processes information through multiple steps:
- Input processing: The model breaks down your prompt into tokens (words or word fragments) and activates features related to those tokens
- Intermediate reasoning: The model activates interconnected features that represent related concepts and potential reasoning pathways
- Output generation: Based on the most strongly activated pathways, the model determines which words to generate next
Let’s look at some specific examples that reveal these hidden mechanisms at work.
Anthropic released two new papers in 2025, both of which represent their progress in developing a ‘microscope’ to understand ‘AI biology’.[7] In the first paper, Anthropic built on previous work in investigating mapping LLMs, revealing the pathways that transform words that enter an AI model and the words that come out the other end. It is a very technical paper. However, the authors provide graphs and illustrations that best demonstrate how the models work. In the second part, the researchers examined Claude 3.5 Haiku to see what happens when the model responds to different prompts. This paper provides excellent illustrative examples, building on the first paper.
Looking Inside AI’s “Thought Process”
Example: Multi-Step Reasoning
When you ask a language model a question requiring multiple reasoning steps, does it perform those steps internally? Research suggests it often does.
Consider this simple example: “What is the capital of the state containing Dallas?”
To answer this correctly (“Austin”), the model must:
- Determine that Dallas is in Texas
- Recall that Austin is the capital of Texas
Using special visualisation tools, researchers observed this exact two-step process happening inside the model. The model activates features representing “Dallas,” which then activate features representing “Texas,” which finally activate features that prompted the model to say “Austin.”
How AI Models Process Information
What the researchers at Anthropic were able to do here is to generate what they call an “attribution graph”.[8] This interactive graph (an example shown below) partially reveals the internal steps a model took to decide on a particular output. Graphs can now be generated on Neuronpedia, allowing users to create and view their graphs from prompts.
To generate a graph, a prompt and a model are selected. Each panel helps to trace the internal steps. There are four features to the interactive graph.
Link or Attribution Graph
This graph displays the model’s reasoning process. Intermediate steps are represented as nodes (the cirlces), with edges indicating the effect of one node on another.
The features of this graph include:
- The input tokens (the prompt broken up) are displayed along the x-axis.
- The likely output tokens are displayed at the top right of the graph. In this example, it is “San”, “Oklahoma, “Dallas”, etc.
- The node with the pink border in layer 7 shows edges connecting to other nodes.
- The nodes in between correspond to ● features, which reflect concepts the model represents in its internal activations.
- The diamonds show ◆ error nodes, which are “missing pieces” not captured by the algorithm.
Node Connections
When you click on a ● feature node in the link/attribution graph, the top right panel will change. It shows its label and connected nodes (sorted by weight).
The mode click in the screenshot below is “[Texas] legal citations and names of places in Texas”. Here, we see lists of its connected nodes, such as “Dallas”, “[Texas] court references and legal terminology”, and “legal documents involving specific Texas locations and people”.
Subgraph
The subgraph on the bottom left serves as a space for interacting with the graph, allowing users to pin and group nodes to make sense of the link graph. For example, it’s where you create a “solution” to what the model is thinking to arrive at its output token.
Feature Details
On the bottom right, where feature details are displayed when hovering over or clicking a node.
- The top activations show the contexts in a dataset that most strongly activated a feature.
- The logits indicate the output tokens that the feature most strongly encourages the model to produce, via direct connections.
- Vaswani, Ashish, et al., 'Attention is all you need' (2017) Advances in neural information processing systems 30 ('Attention is all you need'). ↵
- Bommasani R, Hudson DA, Adeli E et al. (2023) On the Opportunities and Risks of Foundation Models. Centre for Research on Foundation Models (CRFM), Stanford Institute for Human-Centred Artificial Intelligence (HAI), Stanford University. arXiv:2108.07258v3. ↵
- Nguyen, et al. 'Turning up the heat: Min-p sampling for creative and coherent llm outputs' (2024) arXiv preprint arXiv:2407.01082. ↵
- Attention is all you need (no 1). ↵
- Timothy Lee and Sean Trott, 'A jargon-free explanation of how AI large language models work', Arstechnica (online, 31 July 2023) <https://arstechnica.com/science/2023/07/a-jargon-free-explanation-of-how-ai-large-language-models-work/>. ↵
- Ibid. ↵
- Anthropic, 'Tracing the Thoughts of a Large Language Model' (Web Page, 27 March 2025) <https://www.anthropic.com/research/tracing-thoughts-language-model>. ↵
- Anthropic, 'Open-Sourcing Circuit-Tracing Tools', Anthropic Research (Webpage, 29 May 2025) <https://www.anthropic.com/research/open-source-circuit-tracing>. ↵
