18 Prompting a ‘Reasoning’ Model
The introduction of the ‘reasoning’ models represented a significant evolution in generative artificial intelligence (AI) capabilities. These models were designed to tackle complex problems by “spending time thinking before they respond”.[1] Unlike other language models that generate responses in a single forward pass, these models employ a built-in multi-step approach before arriving at an answer. These models break down complex queries into intermediate steps, evaluate different approaches, and can even self-correct their reasoning mid-process. These models have been demonstrated to excel in problem-solving, coding, and scientific and mathematical reasoning.[2]
Moreover, reasoning models represent an evolution in AI architecture, blurring the line between conventional language models and true AI agents. Through sophisticated prompting strategies (such as chain-of-thought or self-consistency), reasoning models can simulate planning, decompose complex queries into subtasks, and check intermediate steps. While these processes are not always implemented as discrete, explicit modules, they approximate some internal mechanisms found in AI agents.
![]() The Models
The Models
‘Reasoning’ models include:
- OpenAI GPT o1, o3-mini
- Claude Sonnet 3.7
- Google’s Gemini 2 Flash Thinking,
- Meta’s LlamaV-o1.
OpenAI started its o-Series with the release of its o1 model in September 2024 and its subsequent o3 and o3-mini models in January 2025.[3] When interacting with them, the interface presents an internal dialogue outlining the steps it takes before arriving at the output.
These models have been trained to ‘think before they answer’.[4] More specifically, they have built-in chain-of-thought processing (discussed in more detail in Prompt Engineering). The terms ‘thinking’ and ‘reasoning’ do not fully represent what is happening here. The approach means that the model will break a problem down into intermediary steps without explicitly being told to do so (other models like GPT-4o need to be given instructions like “Let’s think step by step before answering”). These intermediary steps generate their own tokens, which are then fed back into the prompting process.
 Watch
Watch
Watch this introductory video to learn about OpenAI’s o1 model.
The benefit of these models is their large context windows (o1 has a context window of 128,000 tokens, while o3-mini and Claude 3.7 Sonnet have a context window of 200,000 tokens. Therefore, important information, context, or documents should be provided as part of the prompt, especially if that information is not generally well-known.
As indicated above, these reasoning models introduce ‘reasoning tokens’ alongside input and output tokens. These additional tokens are discarded during multi-step conversations with the model. However, it remains crucial to ensure sufficient space in the context window for reasoning tokens when prompting the model.
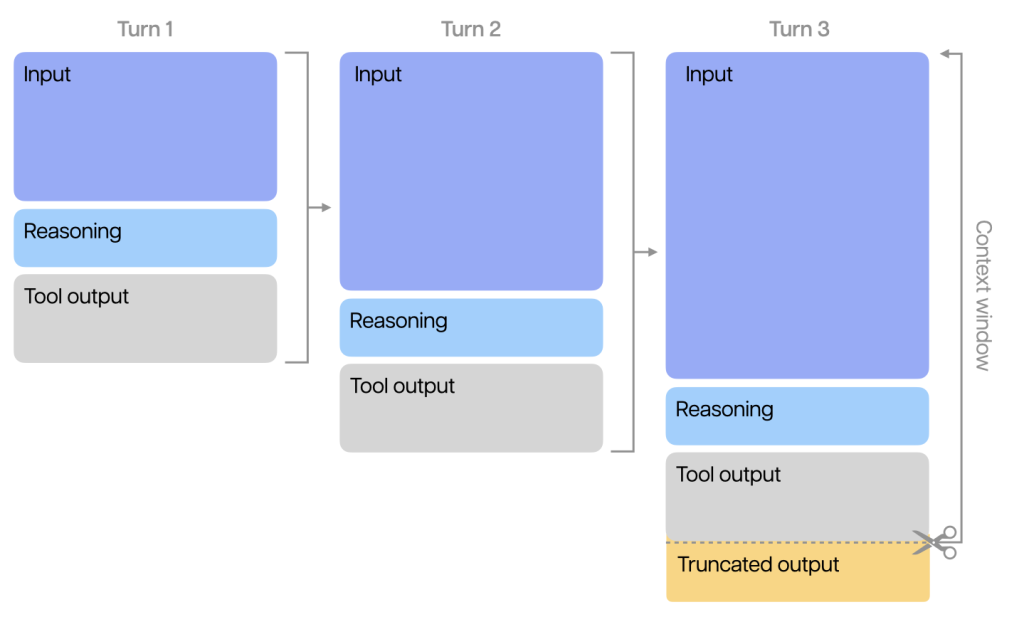
These models can simulate an internal dialogue and can self-check for accuracy. This is why the models are often said to perform ‘thinking’ (although this usage of the term is not entirely accurate). With built-in multi-step processes, these models excel at solving complex problems, coding, and performing scientific reasoning. However, while they are adept at tackling intricate problems, these models may overthink straightforward tasks.
When engaging with these models, you will notice that the outputs are detailed and structured answers. The outputs can also take longer to respond than other models. For example, providing a math problem yields a solution that demonstrates the steps taken and the rationale behind each step. Be prepared for longer and slower outputs. OpenAI released o3-mini as a faster responding model.
OpenAI is not the only one that has these kinds of models. Anthropic’s Claude Sonnet and Opus 4, DeepSeek’s R1, Google’s Gemini 2 Flash Thinking, and Meta’s LlamaV-o1 all seek to offer similar built-in processes.
OpenAI has provided advice on how to choose between GPT and ‘reasoning’ models:[5]
Speed and cost → GPT models are faster and tend to cost less
Executing well-defined tasks → GPT models handle explicitly defined tasks well
Accuracy and reliability → o-series models are reliable decision makers
Complex problem-solving → o-series models work through ambiguity and complexity
They also produced some practical guidance for testing the reasoning models.[6]
1. Navigating ambiguous tasks
Reasoning models are particularly good at taking limited information or disparate pieces of information and with a simple prompt, understanding the user’s intent and handling any gaps in the instructions. In fact, reasoning models will often ask clarifying questions before making uneducated guesses or attempting to fill information gaps.
2. Finding a needle in a haystack
When you’re passing large amounts of unstructured information, reasoning models are great at understanding and pulling out only the most relevant information to answer a question.
3. Finding relationships and nuance across a large dataset
We’ve found that reasoning models are particularly good at reasoning over complex documents that have hundreds of pages of dense, unstructured information—things like legal contracts, financial statements, and insurance claims. The models are particularly strong at drawing parallels between documents and making decisions based on unspoken truths represented in the data.
 How to Prompt a ‘Reasoning’ Model
How to Prompt a ‘Reasoning’ Model
Given the characteristics of these models, prompting a reasoning model is different to other models. Reasoning models excel with broad, high-level guidance, whereas GPT models perform better with specific, precise instructions.
Ben Hylak has described these reasoning models as not being chat models.[7] Therefore, the approach to prompting these models is to give them a brief. Ben has produced a great annotated example prompt for a list of hikes given to o1.[8]
The approach includes:
(a) Setting a Clear Goal — First, define what the output should achieve.
(b) Specify the Format— Specify the type of response needed (lists, summaries, specific fields). The output becomes more useful.
(c) Accuracy Warnings— The model can produce plausible yet inaccurate information, so incorporating accuracy checks helps reduce hallucinations.
(d) The Context Dump — Put context last. This section anchors the model to your specific needs. It avoids generic answers by providing the model with essential constraints and preferences.
OpenAI also provided some advice on how to prompt these models:[9]
These models perform best with straightforward prompts. Some prompt engineering techniques, like instructing the model to “think step by step,” may not enhance performance (and can sometimes hinder it).
- Keep prompts simple and direct: The models excel at understanding and responding to brief, clear instructions.
- Avoid chain-of-thought prompts: Since these models perform reasoning internally, prompting them to “think step by step” or “explain your reasoning” is unnecessary.
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
- Try zero-shot first, then a few-shot if needed: Reasoning models often do not need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
- Provide specific guidelines: If there are ways you explicitly want to constrain the model’s response (like “propose a solution with a budget under $500”), explicitly outline those constraints in the prompt.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
Microsoft provides the following guidance when prompting ‘reasoning’ models:[10]
Use Clear, Specific Instructions:
Clearly state what you want the model to do or answer. Avoid irrelevant details. For complex questions, a straightforward ask often suffices (no need for elaborate role-play or multi-question prompts).
Provide Necessary Context, Omit the Rest:
Include any domain information the model will need (facts of a case, data for a math problem, etc.), since the model might not have up-to-date or niche knowledge. But don’t overload the prompt with unrelated text or too many examples – extra fluff can dilute the model’s focus.
Minimal or No Few-Shot Examples:
By default, start with zero-shot prompts. If the model misinterprets the task or format, you can add one simple example as guidance, but never add long chains of examples for O1/O3. They don’t need it, and it can even degrade performance.
Set the Role or Tone if Needed:
Use a system message or a brief prefix to put the model in the right mindset (e.g. “You are a senior law clerk analysing a case.”). This helps especially with tone (formal vs. casual) and ensures domain-appropriate language.
Specify Output Format:
If you expect the answer in a particular structure (list, outline, etc.), tell the model explicitly. The reasoning models will follow format instructions reliably. For instance: “Give your answer as an ordered list of steps.”
Control Length and Detail via Instructions:
If you want a brief answer, say so (“answer in one paragraph” or “just give a yes/no with one sentence explanation”). If you want an in-depth analysis, encourage it (“provide a detailed explanation”). Don’t assume the model knows your desired level of detail by default – instruct it.
Leverage O3-mini’s Reasoning Effort Setting:
When using O3-mini via API, choose the appropriate reasoning effort (low/medium/high) for the task. High gives more thorough answers (good for complex legal reasoning or tough math), low gives faster, shorter answers (good for quick checks or simpler queries). This is a unique way to tune the prompt behaviour for O3-mini.
Avoid Redundant “Think Step-by-Step” Prompts:
Do not add phrases like “let’s think this through” or chain-of-thought directives for O1/O3; the model already does this internally. Save those tokens and only use such prompts on GPT-4o, where they have impact.
Test and Iterate:
Because these models can be sensitive to phrasing, if you don’t get a good answer, try rephrasing the question or tightening the instructions. You might find that a slight change (e.g. asking a direct question vs. an open-ended prompt) yields a significantly better response. Fortunately, O1/O3’s need for iteration is less than older models (they usually get complex tasks right in one go), but prompt tweaking can still help optimize clarity or format.
Validate Important Outputs:
For critical use-cases, don’t rely on a single prompt-answer cycle. Use follow-up prompts to ask the model to verify or justify its answer (“Are you confident in that conclusion? Explain why.”) or run the prompt again to see if you get consistent results. Consistency and well-justified answers indicate the model’s reasoning is solid.
Applying Best Practices to a Legal Analysis
Microsoft also provides an example of how to approach using a ‘reasoning’ model for a legal analysis scenario:[11]
Legal analysis is a perfect example of a complex reasoning task where O1 can be very effective, provided we craft the prompt well:
Structure the Input: Start by clearly outlining the key facts of the case and the legal questions to be answered. For example, list the background facts as bullet points or a brief paragraph, then explicitly ask the legal question: “Given the above facts, determine whether Party A is liable for breach of contract under U.S. law.” Structuring the prompt this way makes it easier for the model to parse the scenario. It also ensures no crucial detail is buried or overlooked.
Provide Relevant Context or Law: If specific statutes, case precedents, or definitions are relevant, include them (or summaries of them) in the prompt. O1 doesn’t have browsing and might not recall a niche law from memory, so if your analysis hinges on, say, the text of a particular law, give it to the model. For instance: “According to [Statute X excerpt], [provide text]… Apply this statute to the case.” This way, the model has the necessary tools to reason accurately.
Set the Role in the System Message: A system instruction like “You are a legal analyst who explains the application of law to facts in a clear, step-by-step manner.” will cue the model to produce a formal, reasoned analysis. While O1 will already attempt careful reasoning, this instruction aligns its tone and structure with what we expect in legal discourse (e.g. citing facts, applying law, drawing conclusions).
No Need for Multiple Examples: Don’t supply a full example case analysis as a prompt (which you might consider doing with GPT-4o). O1 doesn’t need an example to follow – it can perform the analysis from scratch.. You might, however, briefly mention the desired format: “Provide your answer in an IRAC format (Issue, Rule, Analysis, Conclusion).” This format instruction gives a template without having to show a lengthy sample, and O1 will organize the output accordingly.
Control Verbosity as Needed: If you want a thorough analysis of the case, let O1 output its comprehensive reasoning. The result may be several paragraphs covering each issue in depth. If you find the output too verbose or if you specifically need a succinct brief (for example, a quick advisory opinion), instruct the model: “Keep the analysis to a few key paragraphs focusing on the core issue.” This ensures you get just the main points. On the other hand, if the initial answer seems too brief or superficial, you can prompt again: “Explain in more detail, especially how you applied the law to the facts.” O1 will gladly elaborate because it has already done the heavy reasoning internally.
Accuracy and Logical Consistency: Legal analysis demands accuracy in applying rules to facts. With O1, you can trust it to logically work through the problem, but it’s wise to double-check any legal citations or specific claims it makes (since its training data might not have every detail). You can even add a prompt at the end like, “Double-check that all facts have been addressed and that the conclusion follows the law.” Given O1’s self-checking tendency, it may itself point out if something doesn’t add up or if additional assumptions were needed. This is a useful safety net in a domain where subtle distinctions matter.
Use Follow-Up Queries: In a legal scenario, it’s common to have follow-up questions. For instance, if O1 gives an analysis, you might ask, “What if the contract had a different clause about termination? How would that change the analysis?” O1 can handle these iterative questions well, carrying over its reasoning. Just remember that if the project you are working on, the interface doesn’t have long-term memory beyond the current conversation context (and no browsing), each follow-up should either rely on the context provided or include any new information needed. Keep the conversation focused on the case facts at hand to prevent confusion.
Deep Research Tools
Following the release of their reasoning models, OpenAI introduced their Deep Research tool.[12] This tool represents a sophisticated implementation of AI Agency architecture (see AI Agents for more information), utilising an orchestrator-subagent framework to conduct comprehensive research tasks.
Deep research tools increasingly use a hierarchical, multi-agent architecture in which an AI model deconstructs a complex research query into subtasks, assigns these to specialised subagents (each optimized for tasks like web search, content analysis, or synthesis), and integrates their outputs into a cohesive final answer. This division of labor enables more systematic and comprehensive research than single-model approaches.
The tool essentially functions as a narrow research agent built on OpenAI’s o3 reasoning model, capable of completing multi-step research tasks and synthesising large amounts of online information into report format. Perplexity also offers an equivalent research tool available to users on their free plan, employing similar agency principles.
An introduction
Watch this brief introduction to OpenAI’s Deep Research tool.
However, keep in mind that the information these tools seek to find and synthesise is anything on the internet. The sources they rely on need to be double-checked.
To illustrate the output of these tools, consider the prompt:
How would fair dealing in Australian copyright law apply to digital sampling in music?
An example output of using the Perplexity Deep Research tool can be viewed here: https://www.perplexity.ai/search/thinking-step-by-step-how-woul-ePpoIYg.STCf6BSsQ47Lvw
Using Deep Research
Watch this video that demonstrates how a research tool is used within ChatGPT.
When using these research tools, follow the steps mentioned earlier for prompting reasoning models. A well-structured and thoughtful prompt can help prevent the need for summaries.
Be clear and specific. Avoid vague prompts such as “Tell me about trade mark law.” Frame a precise research question, for example:
Research the distinctiveness requirement under Australian trade mark law.
Provide context and constraints. This is crucial for research in specialised fields. For example:
In the context of intellectual property law, find the latest developments in AI-assisted patent classification systems (2019-2024) and their reported accuracy metrics compared to human examiners.
Set the format of the output. The Deep Research tools will, by default, produce a report, but its format can be guided. For instance: “Provide the answer as a structured report with sections for Background, Key Findings (with sources), and Conclusion.”
Use Role Prompting or set a tone. For example:
You are a legal research assistant…
- OpenAI, 'Introducing OpenAI o1' (Webpage 12 September 2024) <https://openai.com/index/introducing-openai-o1-preview/> ('Introducing OpenAI o1-preview'). ↵
- See OpenAI, 'OpenAI o1-mini' (Webpage 12 September 2024) <https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/>. ↵
- See Introducing OpenAI o1-preview (no 1) and OpenAI, ‘o3-mini’ (Web Page, 31 January 2025) <https://openai.com/index/openai-o3-mini/>. ↵
- Ibid. ↵
- OpenAI, ‘Reasoning Best Practices’, OpenAI Platform (Web Page, 2024) <https://platform.openai.com/docs/guides/reasoning-best-practices> (‘Reasoning Best Practices’). ↵
- Ibid. ↵
- Ben Hylak, ‘o1 isn’t a chat model (and that’s the point)’, Latent Space (Web Page, 12 January 2025) <https://www.latent.space/p/o1-skill-issue>. ↵
- Ibid. ↵
- Reasoning Best Practices (n 3). ↵
- Microsoft, ‘Prompt Engineering for OpenAI’s O1 and O3-mini Reasoning Models’, Axure AI Services Blog (Web Page 5 February 2025) <https://techcommunity.microsoft.com/blog/azure-ai-services-blog/prompt-engineering-for-openai’s-o1-and-o3-mini-reasoning-models/4374010>. ↵
- Ibid. ↵
- OpenAI, ‘Introducing deep research’, OpenAI (Web Page, 2 February 2025) <https://openai.com/index/introducing-deep-research/>. ↵
